
Привет! Меня зовут Валентин Лебедев, я отвечаю за мониторинг в Газпромбанке. Мой опыт в области построения систем мониторинга — более двенадцати лет, из которых последние шесть — строил мониторинг для крупного и сверхкрупного бизнеса.
Статья будет полезна специалистам, строящим ядро/платформу мониторинга, и пользователям, ежедневно с ним взаимодействующим.
Статья будет полезна специалистам, строящим ядро/платформу мониторинга, и пользователям, ежедневно с ним взаимодействующим.

Мы поговорим о пяти этапах взросления мониторинга. Так уж совпало, что эти пять этапов накладываются на сервисные IT-слои:
- Инфраструктурный мониторинг;
- Прикладной мониторинг;
- Бизнес-мониторинг;
- Application Performance Monitoring;
- Real User Monitoring.
Бонус: выясним, как вдохнуть жизнь в мониторинг и сделать его неотъемлемой частью ежедневной работы.
Что такое мониторинг
Мониторинг — это не логи! Нельзя просто развернуть Elastic и Kibana и отчитаться, что теперь у вас есть мониторинг.Мониторинг, в первую очередь, — это проактивность, снижение среднего времени решения значительных инцидентов, повышение надёжности работы сервисов и, как следствие, повышение дохода бизнеса.
Зачем нам нужен каждый из этих блоков:
Проактивность. Проактивная и реактивная детекция сбоя сервиса до первого обращения клиента помогает автоматизированно и вовремя выявлять сбои.
Решение инцидентов. Оперативная локализация места аварии, снижение среднего времени решения значительных инцидентов.
Надёжность. Повышается надёжность, стабильность и качество работы сервиса.
Доход. Повышается финансовая отдача сервиса за счёт повышения надёжности его работы.
Проактивность. Проактивная и реактивная детекция сбоя сервиса до первого обращения клиента помогает автоматизированно и вовремя выявлять сбои.
Решение инцидентов. Оперативная локализация места аварии, снижение среднего времени решения значительных инцидентов.
Надёжность. Повышается надёжность, стабильность и качество работы сервиса.
Доход. Повышается финансовая отдача сервиса за счёт повышения надёжности его работы.
Кажется, что это актуально не только для Газпромбанка.
Огромное количество людей, а также компаний, в том числе международных, постоянно занимаются решением тех же задач. Думаю, всем известны такие инструменты на рынке, как Dynatrace, AppDynamics, Micro Focus (бывший Hewlett Packard).
Огромное количество людей, а также компаний, в том числе международных, постоянно занимаются решением тех же задач. Думаю, всем известны такие инструменты на рынке, как Dynatrace, AppDynamics, Micro Focus (бывший Hewlett Packard).
Коротко про особенности каждого:
Dynatrace — Real User Monitoring, единый агент с хорошим интерфейсом. Но попробуйте растянуть Dynatrace на архитектуру в 6-7 тысяч виртуальных серверов, залить туда логи. Стоимость такого решения будет 600-700 млн в год. Дороговато для функции мониторинга.
AppDynamics — интерфейс взаимодействия чуть хуже, чем у Dynatrace. А ещё у него 52 агента — сложно подобрать, что нужно устанавливать. И, кстати, тоже дорого.
Micro Focus (Hewlett Packard). Он стоит как чугунный мост. А максимум, который можно выжать — это метрики, связанные с CPU, памятью, и, может быть, топики в Kafka.
Проанализировав все решения, мы пришли к выводу: необходимо создавать собственную платформу, развивать её на базе открытого исходного кода. А главным фокусом сделать обеспечение технологической свободы.
Итак, мы начали с первого уровня взросления.
Dynatrace — Real User Monitoring, единый агент с хорошим интерфейсом. Но попробуйте растянуть Dynatrace на архитектуру в 6-7 тысяч виртуальных серверов, залить туда логи. Стоимость такого решения будет 600-700 млн в год. Дороговато для функции мониторинга.
AppDynamics — интерфейс взаимодействия чуть хуже, чем у Dynatrace. А ещё у него 52 агента — сложно подобрать, что нужно устанавливать. И, кстати, тоже дорого.
Micro Focus (Hewlett Packard). Он стоит как чугунный мост. А максимум, который можно выжать — это метрики, связанные с CPU, памятью, и, может быть, топики в Kafka.
Проанализировав все решения, мы пришли к выводу: необходимо создавать собственную платформу, развивать её на базе открытого исходного кода. А главным фокусом сделать обеспечение технологической свободы.
Итак, мы начали с первого уровня взросления.
Уровень 1. Инфраструктурный мониторинг
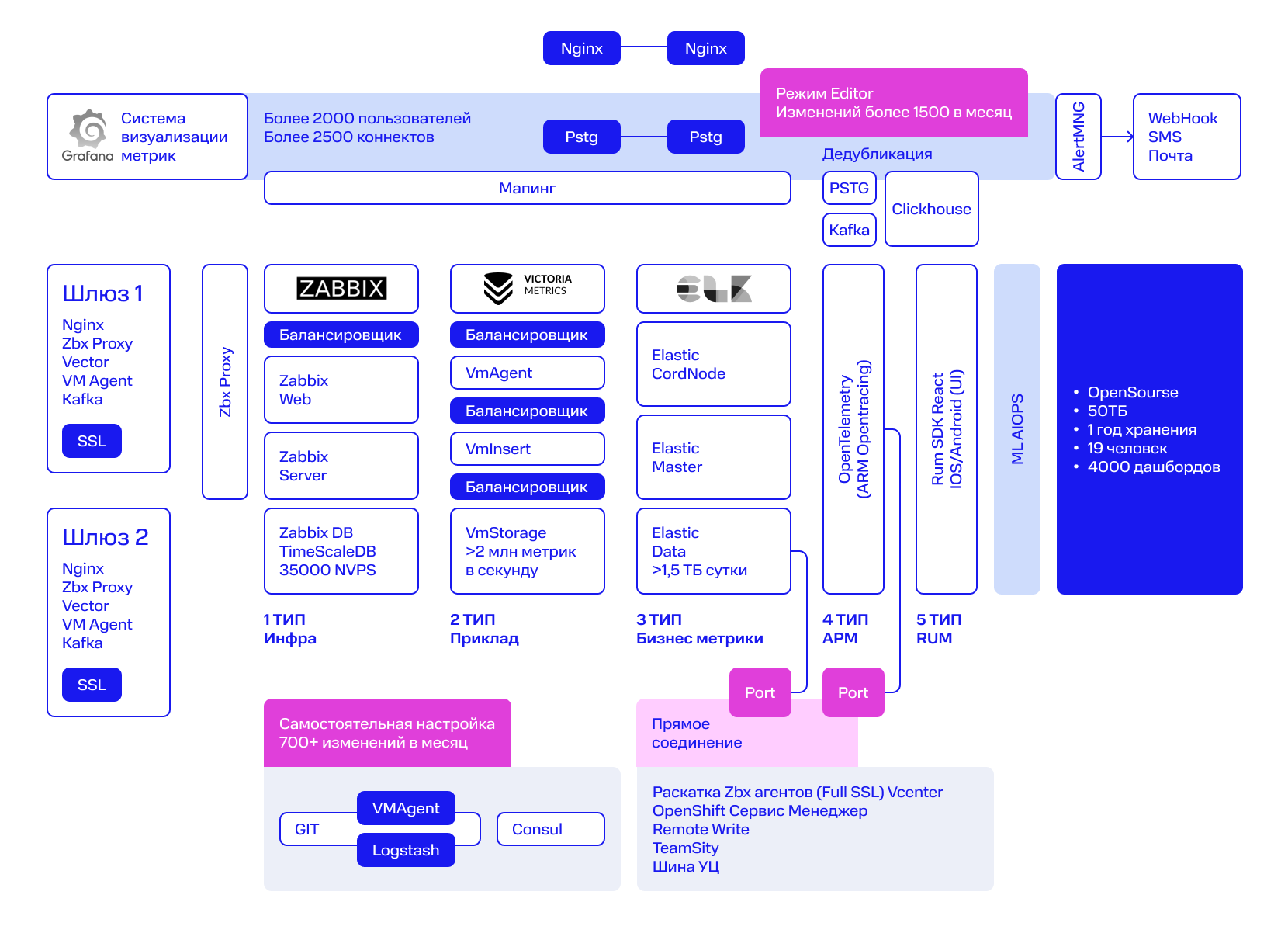
Инфраструктурный мониторинг реализован на Zabbix. У Zabbix — распространенные и легковесные агенты, отличная масштабируемость, он выдерживает высокие нагрузки, у него большое сообщество пользователей и масса шаблонов для сбора телеметрии. Вот некоторые нюансы настройки для обеспечения высокой производительности.Zabbix. Инстансы Zabbix разнесены по отдельным серверам. Это отдельные сущности: Zabbix Web, Zabbix Server, Zabbix DB, Zabbix Proxy. Метрики, которые вы настраиваете, обязательно следует внедрять на уровне Zabbix Proxy. Тем самым вы снизите нагрузку на Zabbix Server.
Под базу данных Zabbix рекомендую ставить TimeScale, потому что именно при такой конфигурации Zabbix в нашей компании выдерживает нагрузку в 35000 NVPS — это более 20 тысяч виртуальных серверов. При большом количество item на одном хосте в обязательном порядке увеличивайте в конфигурации параметр StartAgent - вычислить требуемое количество можно эмпирически
Под базу данных Zabbix рекомендую ставить TimeScale, потому что именно при такой конфигурации Zabbix в нашей компании выдерживает нагрузку в 35000 NVPS — это более 20 тысяч виртуальных серверов. При большом количество item на одном хосте в обязательном порядке увеличивайте в конфигурации параметр StartAgent - вычислить требуемое количество можно эмпирически
Обратите внимание, что к системе Zabbix мы подключаем Grafana.
Все метрики наши команды централизованно получают через Grafana. У Grafana дружелюбные пользовательские инструменты: не нужно предоставлять Admin доступ, достаточно доступов c ролью Editor чтобы пользователи могли самостоятельно строить графики и настраивать алерты.
В Grafana для каждой команды создаются дефолтные инфраструктурные дашборды (основные инфраструктурные метрики хостов + метрики СУБД, Nginx и др), а созданная автоматизация и фильтры отражают хосты и телеметрию со своими данными каждой команды и автоматизированной системы без риска того, что команды увидят метрики соседа.
В Zabbix хосты группируются по мнемокоду (мнемокод — уникальный нейминг сервера, входящего в автоматизированную систему), контуру и стенду. Группировка осуществляется автоматизацией на low-code платформе через API zabbix. Все данные, необходимые для группировки, есть в имени хоста. Есть случаи, когда в имени хоста нет нужной информации либо информация устаревшая. Тогда хост относится к другому контуру или полигону. На этот случай есть заполняемый командами файл csv, где наши коллеги или владельцы АС самостоятельно заполняют файл, который хранится в Bitbucket. На его основе автоматизация дополнительно обогащает хост группами в Zabbix.
Все метрики наши команды централизованно получают через Grafana. У Grafana дружелюбные пользовательские инструменты: не нужно предоставлять Admin доступ, достаточно доступов c ролью Editor чтобы пользователи могли самостоятельно строить графики и настраивать алерты.
В Grafana для каждой команды создаются дефолтные инфраструктурные дашборды (основные инфраструктурные метрики хостов + метрики СУБД, Nginx и др), а созданная автоматизация и фильтры отражают хосты и телеметрию со своими данными каждой команды и автоматизированной системы без риска того, что команды увидят метрики соседа.
В Zabbix хосты группируются по мнемокоду (мнемокод — уникальный нейминг сервера, входящего в автоматизированную систему), контуру и стенду. Группировка осуществляется автоматизацией на low-code платформе через API zabbix. Все данные, необходимые для группировки, есть в имени хоста. Есть случаи, когда в имени хоста нет нужной информации либо информация устаревшая. Тогда хост относится к другому контуру или полигону. На этот случай есть заполняемый командами файл csv, где наши коллеги или владельцы АС самостоятельно заполняют файл, который хранится в Bitbucket. На его основе автоматизация дополнительно обогащает хост группами в Zabbix.
В Grafana каждая автоматизированная система имеет свое пространство — тенант — с источниками данных, которые дают доступ только к их данным. Автоматизация на low-code платформе создаёт в Zabbix отдельную учётную запись без доступа к UI и ограниченную по правам на группу автоматизированную систему. Тенант в Grafana создаёт необходимые источники данных, в которых указывается эта учётная запись, ограниченная только данными автоматизированной системы.
Инфраструктурный дашборд един для всех, он динамический и разделен с помощью переменных, включающих контур, стенд, хост, полигон, тип ОС.
Весь инфраструктурный мониторинг осуществляют прокси, всего их порядка 20. В нагруженных сегментах на каждом прокси примерно по 3к хостов. Новые хосты назначаются на прокси автоматически, учитывая нагрузку прокси, параметр NVPS. Тем самым нагрузка на прокси пропорционально равная. Есть резервные прокси, куда автоматизация может перенести все хосты в случае недоступности основных прокси.
Инфраструктурный дашборд един для всех, он динамический и разделен с помощью переменных, включающих контур, стенд, хост, полигон, тип ОС.
Весь инфраструктурный мониторинг осуществляют прокси, всего их порядка 20. В нагруженных сегментах на каждом прокси примерно по 3к хостов. Новые хосты назначаются на прокси автоматически, учитывая нагрузку прокси, параметр NVPS. Тем самым нагрузка на прокси пропорционально равная. Есть резервные прокси, куда автоматизация может перенести все хосты в случае недоступности основных прокси.
Для мониторинга всего кластера Zabbix, с его сервером, веб частью, прокси и базой данной используется свой дашборд. В дашборд вынесены основные параметры, которые позволяют понять, когда нужно добавить еще один прокси, увеличить ресурсов на БД или добавить дополнительную ноду веб сервера Zabbix.
Основной список метрик, на которые нужно обратить внимание — это пуллеры Zabbix сервера и прокси, которые собираются стандартным шаблоном. Стоит придерживаться 50% процентов занятости пуллеров для запаса по производительности в случае всплесков. И не стоит держать их, если занятость гораздо меньше 50%, ведь тогда пуллеры впустую расходуют ресурсы сервера.
Метрики базы данных — количество сессий, параметр IO wait. Если IO wait — высокий, стоит обратить внимание на тюнинг базы данных. Высокий IO wait говорит о том, что сейчас активно используется диск, а не кэш, и стоит подтюнить базу данных (параметры shared buffer, effective_cache_size, work_mem). Для тюнинга подходит утилита timescaledb tune.
Основной список метрик, на которые нужно обратить внимание — это пуллеры Zabbix сервера и прокси, которые собираются стандартным шаблоном. Стоит придерживаться 50% процентов занятости пуллеров для запаса по производительности в случае всплесков. И не стоит держать их, если занятость гораздо меньше 50%, ведь тогда пуллеры впустую расходуют ресурсы сервера.
Метрики базы данных — количество сессий, параметр IO wait. Если IO wait — высокий, стоит обратить внимание на тюнинг базы данных. Высокий IO wait говорит о том, что сейчас активно используется диск, а не кэш, и стоит подтюнить базу данных (параметры shared buffer, effective_cache_size, work_mem). Для тюнинга подходит утилита timescaledb tune.
Главный параметр в Zabbix, который говорит о проблеме с производительностью - history syncer process. Если он равен 100%, и стандартное увеличение dbsyncer в zabbix server не помогает, это говорит о проблемах с производительностью базы данных, и здесь мы возвращаемся к тюнингу или же говорим о недостаточности ресурсов.
Веб-сервер — количество вызовов, коды ответов, метрики CPU памяти.
Основная нагрузка на веб-сервер идет от Grafana. Тысячи пользователей обращаются за метриками через API Zabbix, используя его веб-сервер. Поэтому обязательно стоит разделять веб часть от Zabbix сервера и балансировать подключения.
Веб-сервер — количество вызовов, коды ответов, метрики CPU памяти.
Основная нагрузка на веб-сервер идет от Grafana. Тысячи пользователей обращаются за метриками через API Zabbix, используя его веб-сервер. Поэтому обязательно стоит разделять веб часть от Zabbix сервера и балансировать подключения.
Уровень 2. Прикладной мониторинг
Мониторинг прикладных метрик мы осуществляем с помощью VictoriaMetrics. Почему не Prometheus? Дело в том, что наш NVPS Prometheus работает нестабильно под высокими нагрузками > 1млн в секунду. В придачу хранилище VictoriaMetrics лучше сжимает данные. Важно, в нашей инсталляции мы НЕ используем ALL IN One.
Для корпоративного использования, каждый инстанс VictoriaMetrics нужно разграничить балансировкой. К такому выводу мы пришли на практике. Также важно, чтобы количество виртуально утилизированной памяти инстансами VictoriaMetrics было ровно в два раза меньше, чем физическая RAM память вашего сервера. Распределенная архитектура позволяет кластеру VictoriaMetrics обрабатывать более 2 млн метрик в секунду.
Мы подключаем VictoriaMetrics к Grafana, и это решение потом используют наши пользователи.
У пользователей благодаря этому появляется возможность в рамках единого окна работать с метриками инфраструктуры и приложения. Сама VictoriaMetrics даёт возможность работать с более чем 300+ агентами мониторинга. Эти агенты нацелены на то, чтобы предоставить гигиенический минимум работы с метриками по таким инстансам, как Apache, Nginx, Kafka и т.п.
У пользователей благодаря этому появляется возможность в рамках единого окна работать с метриками инфраструктуры и приложения. Сама VictoriaMetrics даёт возможность работать с более чем 300+ агентами мониторинга. Эти агенты нацелены на то, чтобы предоставить гигиенический минимум работы с метриками по таким инстансам, как Apache, Nginx, Kafka и т.п.
Уровень 3. Бизнес-мониторинг
В основе работы с бизнес-метриками используется Elasticsearch. Мы работаем с логами и метриками, получаемыми посредством SQL-запросов к БД. Стоит отметить, что на уровне ElasticSearch мы подразумеваем использование хранилища БД Elasticsearch. Да, у нас нет Kibana в качестве UI для просмотра логов, а в части слоя обработки мы рекомендуем Vector — он идеально подходит для вычитки больших объёмов (100/500 мб/с) логов из Kafka.
Проведя нагрузочное тестирование, мы пришли к выводу, что Logstash обрабатывает один и тот же объём данных за 32 Гб оперативной памяти. А Vector обрабатывает тот же объём за 3 Гб оперативной памяти. Естественно, мы не могли не воспользоваться таким инструментом в нашей платформе мониторинга.
Стоит отметить, что мониторинг — про метрики, а не про логи. В наших LM политиках мы обозначаем, что чистые логи храним одни сутки, а дальше с помощью инструмента Transform Aggregation конвертируем логи в метрики. Так мы увеличиваем глубину хранения метрик и оптимизируем стоимость хранения.
Для обеспечения высокой скорости и обработки логов кластер Elasticsearch имеет распределенную архитектуру:
Для обеспечения высокой скорости и обработки логов кластер Elasticsearch имеет распределенную архитектуру:
- MasterNode;
- DataNode;
- Coordination Node.
Нашим пользователям в едином окне доступны инфраструктурный мониторинг, прикладной мониторинг и мониторинг бизнес метрик. То есть появляется режим Business Impact Analysis (BIA), когда вы точно понимаете, как работают ваши виртуальные машины, что у вас с работой приложений и как их просадка влияет на бизнес-метрики. Бизнес-метрики — это количество выданных кредитов, количество транзакций, количество переводов или покупок, которые осуществляются в ваших сервисах.
Как показывает практика, в компаниях на этих трёх уровнях чаще всего и останавливаются. Почему-то считается, что этого достаточно. Но наши пользователи хотят понять, как развивается и живёт их сервис с точки зрения транзакционной активности соединяя воедино цепочку запросов проходящих через множество систем, тем самым обеспечивая сервис пользователям.
И мы переходим к четвёртому и пятому уровням взросления мониторинга.
Как показывает практика, в компаниях на этих трёх уровнях чаще всего и останавливаются. Почему-то считается, что этого достаточно. Но наши пользователи хотят понять, как развивается и живёт их сервис с точки зрения транзакционной активности соединяя воедино цепочку запросов проходящих через множество систем, тем самым обеспечивая сервис пользователям.
И мы переходим к четвёртому и пятому уровням взросления мониторинга.
Уровень 4. Application Performance Monitoring (APM)
Application Performance Monitoring — это мониторинг показателей работы приложений ваших сервисов и транзакционных цепочек связи ваших сервисов между собой Tracing\Span время каждого вызова (что, где тормозит и сколько грузится, код ответа, ошибки, время обращения в СУБД в т.ч. с регистрацией SQL-запросов. Для реализации данного типа мониторинга мы подняли универсальный коллектор, который анонсируем на нашей платформе. На него можно принимать соответствующие спаны и трассировки в зависимости от технологий, используемых командами на своей стороне (Zipkin, Jeger, OpenTеlemetry, OtelCollector). Все данные попадают в единое хранилище Elasticsearch в нужные индексы.
В качестве UI отображения цепочек трассировок и просмотра трэйсов мы используем единый UI Grafana, Plugin Jaeger, что позволяет нашим командам дообогатить свои дашборды с трёх уровней телеметрией по работе их сервисов и приложений в рамках единого дашборда.
Уровень 5. Real User Monitoring
Разница Application Performance Monitoring и Real User Monitoring в том, как мы видим транзакционную активность и как живёт сервис внутри IT-ландшафта:
- на уровне APM — до уровня межсетевого экрана, внутри периметра компании;
- на уровне Real User Monitoring захватываем метрики уже из самого сегмента интернета с наших мобильных устройств, WEB UI, и транспортируем их к нам в платформу мониторинга;
- на уровне RUM мы видим каждый клик и каждую ошибку с которой столкнулся наш пользователь при работе в мобильном приложении или web UI
Для реализации Real User Monitoring на GitHub в открытом доступе есть библиотеки, например, New Relic SDK OpenSource агенты или их аналоги. Их можно скачать, проинжектировать в мобильное приложение и начать получать метрики прямо в платформу мониторинга. На бэкенде вы должны будете произвести работу для приёма телеметрии RUM. В зависимости от ваших данных рекомендуем как минимум делать шифрование и использовать CSRF. Для снижения трафика используйте компрессию перед шифрованием.
Для отображения метрик RUM на бэкенде мы также используем Plugin Grafana, т.е. команды могут получать и обогащать телеметрией RUM все 5 уровней мониторинга в одном UI, а также проводить аналитику воронок продаж и исследовать каждое обращение клиентов с проблемой.
Бывает, что колл-центр сообщает о скачке числа обращений — непонятно, что у них происходит, фактура для исследования чаще всего субъективная. Естественно, просят срочно разобраться.
Для отображения метрик RUM на бэкенде мы также используем Plugin Grafana, т.е. команды могут получать и обогащать телеметрией RUM все 5 уровней мониторинга в одном UI, а также проводить аналитику воронок продаж и исследовать каждое обращение клиентов с проблемой.
Бывает, что колл-центр сообщает о скачке числа обращений — непонятно, что у них происходит, фактура для исследования чаще всего субъективная. Естественно, просят срочно разобраться.
Преимущество централизованной архитектуры в том, что все 5 типов мониторинга в наших командах в Газпромбанке (эксплуатация, разработка, технические директора, колл-центр, ситуационный центр) работают в едином графическом пространстве. Наши технические эксперты, заглянув в единое окно мониторинга, могут абсолютно точно определить, сколько клиентов столкнулись с проблемой, какие ошибки и в какой версии мобильного приложения возникли. Дальше, разматывая цепочку вглубь, мы точно понимаем, где произошла проблема. Работая с единым источником правды, у нас всегда повышается доверие в коммуникации.

Итак, мы проговорили 5 уровней взросления мониторинга:
- инфраструктура;
- прикладной мониторинг;
- бизнес-метрики;
- Application Performance Monitoring;
- Real User Monitoring.
- 35000 NVPS на уровне Zabbix;
- 2 млн метрик в секунду на уровне VictoriaMetrics;
- при штатной работе 1,5 ТБ (В пике до 4,5 ТБ) в сутки на уровне Elasticsearch.
Как разбалансировать нагрузку
Внутри компании мы собрали универсальный шлюз, позволяющий работать с метриками, логами и трассировками. Этот шлюз состоит из Nginx, Kafka, Vector, Zbx Proxy и VM Agent. Шлюз:
Внутри компании мы собрали универсальный шлюз, позволяющий работать с метриками, логами и трассировками. Этот шлюз состоит из Nginx, Kafka, Vector, Zbx Proxy и VM Agent. Шлюз:
- балансирует нагрузку;
- позволяет управлять направлением движения трафика на уровне информационной безопасности. Это когда нужно развернуть его либо с DMZ в сторону LAN-сегмента, либо с точки зрения LAN, PCI DSS.
Кстати, информационная безопасность максимально позитивно встречает такие шлюзы, так как они закрывают требования по управлению движением трафика и защитой передаваемых данных.
Ежедневно Grafana пользуется 2-2,5 тысяч человек. Нагрузки большие, поэтому перед Grafana установлены балансировщики. SQLite мы отбрасываем, вместо неё устанавливаем кластер PostgreSQL. Внутренний алерт-менеджер Grafana интегрируем с корпоративным мессенджером: Telegram, почтой — любой удобный вариант. Отдельное внимание уделим дедупликации.
Ежедневно Grafana пользуется 2-2,5 тысяч человек. Нагрузки большие, поэтому перед Grafana установлены балансировщики. SQLite мы отбрасываем, вместо неё устанавливаем кластер PostgreSQL. Внутренний алерт-менеджер Grafana интегрируем с корпоративным мессенджером: Telegram, почтой — любой удобный вариант. Отдельное внимание уделим дедупликации.
Дедупликация
Платформа мониторинга Газпромбанка отправляет 36 млн алерт-сообщений в неделю. Такой объем алертов обусловлен большим количеством команд, метрик мониторинга, сервисных метрик, разной клиентской активностью.
Настройка алертов — это всегда поиск золотой середины между чувствительностью и точностью срабатывания. Мониторинг — это единая точка правды, платформа, которой верят. Поэтому отправляемые платформой критические алерты должны быть максимально очищенными от шума. Когда видишь 20 тысяч сообщений в чате с утра, доверие к этому чату быстро пропадает, — так же и с платформой мониторинга.
Платформа мониторинга Газпромбанка отправляет 36 млн алерт-сообщений в неделю. Такой объем алертов обусловлен большим количеством команд, метрик мониторинга, сервисных метрик, разной клиентской активностью.
Настройка алертов — это всегда поиск золотой середины между чувствительностью и точностью срабатывания. Мониторинг — это единая точка правды, платформа, которой верят. Поэтому отправляемые платформой критические алерты должны быть максимально очищенными от шума. Когда видишь 20 тысяч сообщений в чате с утра, доверие к этому чату быстро пропадает, — так же и с платформой мониторинга.
В платформе мониторинга мы реализовали общую автоматику дедупликации и шумоподавления. Автоматика обрабатывает все события, генерируемые платформой. Все: вне зависимости от того, были это алерты, настроенные в рамках золотого образа метрик, или реализованные в режиме MaaS силами команд. Суть автоматики в том, чтобы убрать или сгладить дребезжащие алерты. Эти алерты неминуемы при наблюдении за сервисом. Автоматизация снижает общий объём отправляемых событий в 35 раз.
Архитектурно дедубликация собрана из Postgres, Kafka, Clickhouse. В ней реализована логика оперативного хранилища с сохранением алертов в очереди, их анализ по уникальному ключу события и дальнейшее схлопывание алертов в одно открывающее или закрывающее событие.
Архитектурно дедубликация собрана из Postgres, Kafka, Clickhouse. В ней реализована логика оперативного хранилища с сохранением алертов в очереди, их анализ по уникальному ключу события и дальнейшее схлопывание алертов в одно открывающее или закрывающее событие.
Если вкратце:
- Отправляем все ивенты в Kafka.
- Сервис вычитывает все события и записывает их статусы, id-проверки, и id события в бд, uid временного ряда.
- Отправляем открытые алерты получателям по каналам.
- Если получены новые алерты со статусом “открыт” и таким же id-проверки — подавляем их.
- Если получены алерты с таким же id и закрывающим статусом, производим запись в кэш и ожидаем несколько минут.
- Если получен новый алерт такого же типа со статусом “открытый” — подавляем. Если получено новое событие со статусом “открыто” и таким же статусом для id-проверки, а алерт ожидает статуса «закрыто», то отправка не производится. В этом блоке также учитываются механизмы repeat и отложенных уведомлений;
Важно не забывать про набор тегов, позволяющих управлять дедупликацией: время начала\окончания рассылки уведомлений, дни недели, по которым работать, управление периодом повторения (repeat), каналами доставки, заголовком и текстом сообщений с их критичностью.
7. Если за несколько минут новых алертов с тем же id-проверки не получено, производим запись смены статуса и отправку закрывающего события.
Безусловно, модули дедупликации — неотъемлемая часть платформы мониторинга, на основе данных модулей происходит чистка данных и дообагащение требуемыми параметрами.
7. Если за несколько минут новых алертов с тем же id-проверки не получено, производим запись смены статуса и отправку закрывающего события.
Безусловно, модули дедупликации — неотъемлемая часть платформы мониторинга, на основе данных модулей происходит чистка данных и дообагащение требуемыми параметрами.
По нашей дорожной карте уже ведётся разработка централизованного модуля управления событиями и алертами. Доработка предусматривает:
- умный алертинг — работа с метриками на основе динамических бэйзлайнов;
- централизацию обработки всех алертов, чтобы проводить сложную корреляцию и руткост;
- обогащения событий требуемыми параметрами на основе CMDB.
MaaS: набор инструментов для самостоятельной настройки мониторинга
Статья называется «Мониторинг как сервис». Это значит, что мониторинг должен работать примерно как парикмахерская — пришёл, заплатил 300 рублей, получил услугу. Только в нашем случае заказчики всей компании приходят к команде мониторинга и просят установить нужные метрики.
Но что если MaaS — не сервис, а платформа, коробка мониторинга, в которой есть инструменты для самостоятельной настройки метрик?
Давайте рассмотрим, как мы реализовали такой подход на уровне описанной выше архитектуры:
- На уровне Grafana открыли доступ Editor. Благодаря этому наши пользователи могут самостоятельно настраивать новую визуализацию метрик и устанавливать алерты.
- На уровне Elasticsearch и OpenTelemetry анонсировали порты, открыли их и стандартизировали формат логов, которые можно заливать в платформу. Благодаря этому наши пользователи знают, куда отправлять логи и трассировки.
- Интегрировали платформу с системой.
- Предоставили value-стримам такие инструменты, как контейнерный VM-агент и контейнерный Logstash.
Logstash будет использоваться для SQL-запросов, VM-агент и Consul — взаимодействовать с точки зрения доставки конфигурации новых экспортёров в платформу мониторинга.
Как показывает практика, мониторинг нужен не завтра, и не через месяц, а прямо сейчас. Получая инструменты самостоятельной загрузки SQL, VM-агентов, логов и понимание, как именно это делать, команды тут же получают требуемые метрики в мониторинге. Такая конфигурация подходов предоставляет свободу изменений на уровне графиков, алертов. Вы можете загружать конфигурации экспортёров, логов, работать с бизнес-метриками, цепочками транзакционной активности внутри сервисов.
Так мы делегировали 2200 задач в месяц. Это говорит о том, что наши заказчики самостоятельно включили необходимые им параметры мониторинга и вернулись к нам с огромной позитивной обратной связью. Потому что они получили то, что хотели, здесь и сейчас.
Так мы делегировали 2200 задач в месяц. Это говорит о том, что наши заказчики самостоятельно включили необходимые им параметры мониторинга и вернулись к нам с огромной позитивной обратной связью. Потому что они получили то, что хотели, здесь и сейчас.
Для повышения эффективности команде мониторинга необходимо централизованно подключить платформу мониторинга к таким сущностям, как Kubernetes, OpenShift, Сервис-Менеджер, системы Б-копирования, удостоверяющего центра. А ещё проработать вопрос централизованной раскатки инфраструктурных агентов в IT-ландшафт банка.
Такие интеграции дают две потенциальные выгоды:
- Возможность создания Золотых дашбордов (преднастроенных дашбордов по сервисам).
- В случае необходимости команды получают доступ к необходимым дататосорсам и самостоятельно строят под себя графики и алерты, не затрачивая время на точечные интеграции.
Какие ресурсы под капотом платформы мониторинга
Платформа утилизирует 50 ТБ жесткого диска, глубина хранения — год. Я практически убежден, что 50 ТБ — это объём жестких дисков у вас дома, на которых вы храните фотографии и видео.
В системе 4 тысячи дашбордов, 500 из которых построила команда мониторинга в 19 человек, а 3,5 тысячи — непосредственно реализовали наши заказчики.
Чек-лист для команды мониторинга:
- соберите архитектуру платформы мониторинга;
- развивайте автоматику (автоматическая раскатка агентов);
- стандартизируйте и откройте порты для приёма данных.;
- откройте доступ Editor в Grafana (алертинг + дашборды);
- внедряйте золотые дашборды и алерты.
Команда мониторинга централизованно подключается к Kubernetes, OpenShift и т.п. Благодаря этому заказчики из коробки получают гигиенический минимум:
- инфраструктурный дашборд;
- дашборд мониторинга СУБД;
- дашборд Nginx, Kafka, другое;
- мониторинг сертификатов;
- мониторинг OpenShift, Kuber;
- мониторинг Vcenter;
- дашборд деплоев;
- дашборд инцидентов.
При централизованной интеграции платформы вы получаете инфраструктурный мониторинг как промышленных, так и тестовых серверов, мониторинг БД, Nginx, количества значительных инцидентов по бэкапам, сертификатам, работе подов и многое другое, что так важно командам иметь под рукой для оценки работоспособности сервиса и внешнего фона.
Бонусная часть: оживляем мониторинг
Я убеждён, что большинство инструментов на слуху и так или иначе используются в компаниях. Перечисленными возможностями сложного кого-то удивить. Но почему тогда так часто мониторинг становится «мёртвым» и мало используемым сервисом? Чтобы мониторинг использовался, он должен решать конкретные задачи: проактивное открытие инцидентов, снижение стоимости их решения, повышение стабильности и надёжности работы сервисов.
Давайте разберём шаги, которые оживляют мониторинг:
1. Собираем значительные инциденты
Совместно с КЦ и Первой линией поддержки определите Топ-10 значительных инцидентов компании и совместно с командами проработайте постановку на мониторинг данных сервисов. Как показывает практика, топ-10 значительных инцидентов — это в среднем 50-60% головной боли, которая поступает от клиента. Отнесите этот список командам и проработайте постановку этих автоматизированных систем и сервисов на мониторинг, чтобы определять остановку данных сервисов через автоматизированные средства мониторинга.
2. Организовываем реверс-процесс
При разборе значительных инцидентов на комиссии по инцидентам выявляйте те, которые не выявил мониторинг. В каждой компании хотя бы раз в неделю обсуждают инциденты. Первое, с чего должно начинаться обсуждение значительных инцидентов, — выявил ли его мониторинг или он поступил от клиента. Если инцидент поступил от клиента, необходимо отправить фактуру в команды и поставить соответствующие метрики в мониторинг для возможности выявления подобных инцидентов через мониторинг.
Совместно с КЦ и Первой линией поддержки определите Топ-10 значительных инцидентов компании и совместно с командами проработайте постановку на мониторинг данных сервисов. Как показывает практика, топ-10 значительных инцидентов — это в среднем 50-60% головной боли, которая поступает от клиента. Отнесите этот список командам и проработайте постановку этих автоматизированных систем и сервисов на мониторинг, чтобы определять остановку данных сервисов через автоматизированные средства мониторинга.
2. Организовываем реверс-процесс
При разборе значительных инцидентов на комиссии по инцидентам выявляйте те, которые не выявил мониторинг. В каждой компании хотя бы раз в неделю обсуждают инциденты. Первое, с чего должно начинаться обсуждение значительных инцидентов, — выявил ли его мониторинг или он поступил от клиента. Если инцидент поступил от клиента, необходимо отправить фактуру в команды и поставить соответствующие метрики в мониторинг для возможности выявления подобных инцидентов через мониторинг.
3. Выявляем топ-10 метрик
Команды определяют топ-10 метрик по их сервису и передают эти параметры на мониторинг. В мониторинг можно загрузить сотни, тысячи, может быть, десятки тысяч всевозможных метрик. Но важно из этого массива выделить критические, которые абсолютно точно покажут, работает сейчас сервис или нет.
Команды определяют топ-10 метрик по их сервису и передают эти параметры на мониторинг. В мониторинг можно загрузить сотни, тысячи, может быть, десятки тысяч всевозможных метрик. Но важно из этого массива выделить критические, которые абсолютно точно покажут, работает сейчас сервис или нет.
Что нам дал мониторинг
В Газпромбанке перечисленные подходы обеспечили 75-80% проактивного открытия инцидентов ещё до первого обращения клиента.
Мы на 30-40% сократили среднее время решения значительных инцидентов, а по некоторым направлениям сервиса получили десятикратный рост повышения стабильности работы.
Бытует мнение, что команды поддержки, value-стримы, разработчики не загружают метрики в мониторинг, потому что все увидят, когда сервис не работает, а это привлечет лишнее внимание и поиск виновных. Но давайте здраво: загруженные в мониторинг метрики дают точное понимание, что нужно сделать с нашим сервисом и как его усовершенствовать, чтобы он работал качественней и стабильнее. А качество работы сервиса — это главное конкурентное преимущество.





.png)


