

Как бороться с типовыми причинами отказа? А самое главное — как их обнаружить? Рассмотрим лучшие элементы инженерной практики, обеспечивающие высокую доступность системы и оперативное расследование инцидентов. Коснёмся памяти, разберём базу данных, поговорим про ТСР-соединения.
Меня зовут Константин, я работаю в Газпромбанке. Занимаюсь транзакционными системами: платежами, переводами, также участвовал в разработке системы СБП в Газпромбанке. В своей практике столкнулся с десятками языков программирования, но в настоящий момент остановился на Java и Kotlin. Поэтому я буду рассказывать про проблемы backend разработки на этих языках.
Меня зовут Константин, я работаю в Газпромбанке. Занимаюсь транзакционными системами: платежами, переводами, также участвовал в разработке системы СБП в Газпромбанке. В своей практике столкнулся с десятками языков программирования, но в настоящий момент остановился на Java и Kotlin. Поэтому я буду рассказывать про проблемы backend разработки на этих языках.
Highload для разработчика?
Я часто провожу технические собеседования, ассессменты, и мне очень нравится задавать вопрос: «Работал ли ты с highload-системами?». Можно по ответу понять, как себя чувствует разработчик. Если это джун, он начинает стесняться, сомневаться, отказывается отвечать или говорит, что не работал. Мидл начинает спорить про RPS и ТРS, мериться цифрами. Сеньоры начинают задумываться и задавать встречные вопросы: «А что такое highload-система для тебя? Как ты оцениваешь эту систему?».
Наверняка у каждого из вас есть свой ответ на вопрос, что же такое highload-система. Для меня это система, которой недостаточно стандартной инфраструктуры, настроек, чтобы обслуживать поступающие запросы. Это система, которую необходимо “твикать” и точно настраивать. Например, вы развернули PostgreSQL в докере и вам этого хватает, поэтому вы никогда не задумывались про ТСР-соединения, и, скорее всего, у вас не highload.
Вот основные понятия/метрики, связанные с высоконагруженными системами:
→ Высокая нагрузка.
Потребление памяти сервисов может вырасти в результате повышения нагрузки, и это не всегда линейный процесс
→ Неправильная конфигурация.
В последнее время участились внедрения систем виртуализации: Kubernetes, OpenShift, Docker. И не все понимают, как правильно их настраивать. Если настройку сделать некорректно, высок риск out of memory.
→ Неожиданные бизнес-данные.
Когда вы пишете и тестируете код, вы не всегда представляете с каким количеством данных он будет работать. Внезапно могут измениться бизнес-условия, и вместо 1 000 транзакций на вход поступит 100 000. Код к такому может быть не готов, и, соответственно, вы получаете падение.
→ Утечка памяти.
Несмотря на то, что большинство современных языков программирования самостоятельно управляют памятью, тем не менее разработчики иногда допускают ошибки, создают цепочки зависящих друг от друга объектов. Garbage collector не справляется с этими испытаниями, и возникают утечки памяти.
У нас есть график потребления памяти одного микросервиса:
Вот основные понятия/метрики, связанные с высоконагруженными системами:
- RPS/RPM, Requests Per Second (Minute) → Профилирование приложения
- TPS/TPM, Transactions Per Second (Minute) → Анализ дампов памяти
- TCP/HTTP/JDBC/JMS pools → Анализ/оптимизация запросов в БД
Память
Популярные проблемы, с которыми вы можете столкнуться:→ Высокая нагрузка.
Потребление памяти сервисов может вырасти в результате повышения нагрузки, и это не всегда линейный процесс
→ Неправильная конфигурация.
В последнее время участились внедрения систем виртуализации: Kubernetes, OpenShift, Docker. И не все понимают, как правильно их настраивать. Если настройку сделать некорректно, высок риск out of memory.
→ Неожиданные бизнес-данные.
Когда вы пишете и тестируете код, вы не всегда представляете с каким количеством данных он будет работать. Внезапно могут измениться бизнес-условия, и вместо 1 000 транзакций на вход поступит 100 000. Код к такому может быть не готов, и, соответственно, вы получаете падение.
→ Утечка памяти.
Несмотря на то, что большинство современных языков программирования самостоятельно управляют памятью, тем не менее разработчики иногда допускают ошибки, создают цепочки зависящих друг от друга объектов. Garbage collector не справляется с этими испытаниями, и возникают утечки памяти.
У нас есть график потребления памяти одного микросервиса:
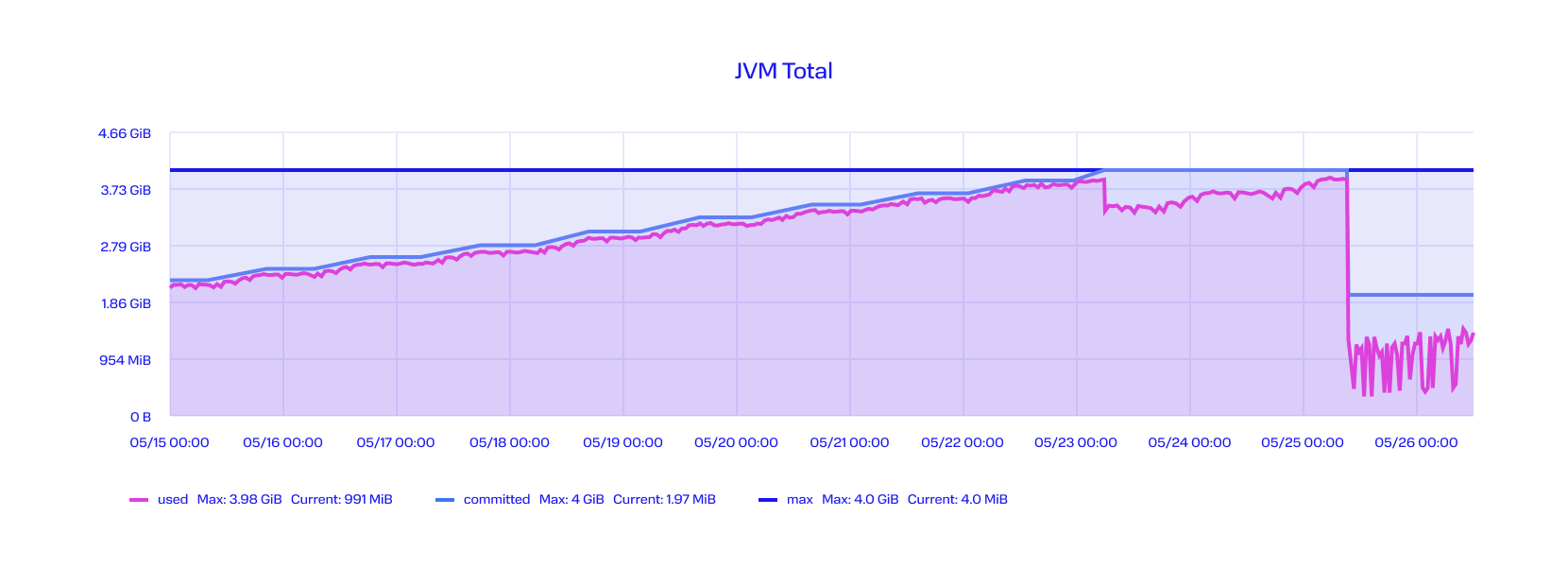
Как видно, в конце, он не выдержал. Случилась ошибка out of memory и последующая перезагрузка.
По графику видно, что временной период — 10 дней, то есть это долгий процесс. А значит, мы имеем дело с утечкой памяти.
Давайте посмотрим, с чем эта утечка была связана.
Мы разрабатывали систему логирования, и библиотека для логирования должна была фиксировать запрос и ответ, временную разницу между ними. Разработчик не учёл, что у нас есть ещё запросы в MQ, которые не всегда получают ответы. Есть асинхронное взаимодействие, где формируется только запрос, а ответа уже не поступает. И в этой точке начали накапливаться события системы логирования. Они не закрывались, не удалялись. И постепенно, в течение 10 дней, это всё убивало сервис.
Как справляться с утечками? Утечка памяти, обязательно, в какой-нибудь момент случится. Особенно, если система — развивающаяся, и ваши сотрудники периодически производят в ней новые доработки. Шанс ошибиться всегда есть, бояться этого не стоит. Нужно проинструктировать, людей, сопровождающих ваш пром, о том, как с этим бороться: как только сервис начинает падать по памяти, нужно сразу снимать heap dump.
Но есть нюанс. Если вы снимаете heap dump с прода, пожалуйста, не заливайте такие дампы в паблик шары и не выдавайте разработчикам на анализ, потому что в дампе с прода могут оказаться пароли от ТУЗов и прочие чувствительные данные пользователей. Поэтому анализировать их лучше тем же сотрудникам, которые сопровождают пром.
Анализ тривиален. Есть прекрасные инструменты. Например, memory analyzer tool от Эклипса. Загружаете дамп и инструмент сразу же «предполагает», где утечка. И часто действительно это происходит там, где он указал. Кроме этого, можно снимать периодические дампы памяти. Есть инструмент JProfiler, который умеет сравнивать между собой несколько heap dump. Также рекомендую с помощью стандартных средств мониторинга - Микрометра, Prometheus и Grafana настраивать превентивную реакцию. Мы настроили алерты так, что когда любой из сервисов достигает потребления памяти в 95% от допустимого лимита, сразу же подключается поддержка. Они снимают heap dump и перезагружают сервис, чтобы вернуть его в норму. Дальше heap dump уже анализируется и расследуется первопричина проблемы.
Неожиданные бизнес-данные
У нас была задача — выгружать отчёты по транзакциям. Когда аналитики проектировали этот процесс, они примерно представляли, какими объемами клиенты будут выгружать информацию. Приняли решение: один POS терминал в день производит около 3500 операций. Такой объем легко помещается в памяти приложения, даже если запланировать увеличение в два раза. Поэтому минимальный блок для выгрузки приняли за количество транзакций по одному терминалу в один день.
Этот бизнес-процесс прекрасно работал на протяжении двух или трёх лет. Но в какой-то момент начали запускаться транспортные проекты, терминалы стали ставить в автобусах. Изменилась механика работы, выросла скорость. И, самое интересное, операции с этих терминалов агрегировались на один виртуальный терминал. Тот отчёт, который раньше работал с 5–7 тысячами транзакций, теперь начал подгружать 500 000–1 000 000 транзакций.
Что же произойдет с системой в этом случае? Представим, что сотрудник запустил выгрузку. Сервис загрузил 500 000 транзакций и начал их обрабатывать. Сотрудник оказался нетерпелив, в течение 20 минут он не дождался своего отчёта и решил перезапустить выгрузку. Сервис подгрузил еще 500 000 транзакций и в итоге мы получили график потребления памяти с двумя пиками на временном интервале в пол часа:
По графику видно, что временной период — 10 дней, то есть это долгий процесс. А значит, мы имеем дело с утечкой памяти.
Давайте посмотрим, с чем эта утечка была связана.
Мы разрабатывали систему логирования, и библиотека для логирования должна была фиксировать запрос и ответ, временную разницу между ними. Разработчик не учёл, что у нас есть ещё запросы в MQ, которые не всегда получают ответы. Есть асинхронное взаимодействие, где формируется только запрос, а ответа уже не поступает. И в этой точке начали накапливаться события системы логирования. Они не закрывались, не удалялись. И постепенно, в течение 10 дней, это всё убивало сервис.
Как справляться с утечками? Утечка памяти, обязательно, в какой-нибудь момент случится. Особенно, если система — развивающаяся, и ваши сотрудники периодически производят в ней новые доработки. Шанс ошибиться всегда есть, бояться этого не стоит. Нужно проинструктировать, людей, сопровождающих ваш пром, о том, как с этим бороться: как только сервис начинает падать по памяти, нужно сразу снимать heap dump.
Но есть нюанс. Если вы снимаете heap dump с прода, пожалуйста, не заливайте такие дампы в паблик шары и не выдавайте разработчикам на анализ, потому что в дампе с прода могут оказаться пароли от ТУЗов и прочие чувствительные данные пользователей. Поэтому анализировать их лучше тем же сотрудникам, которые сопровождают пром.
Анализ тривиален. Есть прекрасные инструменты. Например, memory analyzer tool от Эклипса. Загружаете дамп и инструмент сразу же «предполагает», где утечка. И часто действительно это происходит там, где он указал. Кроме этого, можно снимать периодические дампы памяти. Есть инструмент JProfiler, который умеет сравнивать между собой несколько heap dump. Также рекомендую с помощью стандартных средств мониторинга - Микрометра, Prometheus и Grafana настраивать превентивную реакцию. Мы настроили алерты так, что когда любой из сервисов достигает потребления памяти в 95% от допустимого лимита, сразу же подключается поддержка. Они снимают heap dump и перезагружают сервис, чтобы вернуть его в норму. Дальше heap dump уже анализируется и расследуется первопричина проблемы.
Неожиданные бизнес-данные
У нас была задача — выгружать отчёты по транзакциям. Когда аналитики проектировали этот процесс, они примерно представляли, какими объемами клиенты будут выгружать информацию. Приняли решение: один POS терминал в день производит около 3500 операций. Такой объем легко помещается в памяти приложения, даже если запланировать увеличение в два раза. Поэтому минимальный блок для выгрузки приняли за количество транзакций по одному терминалу в один день.
Этот бизнес-процесс прекрасно работал на протяжении двух или трёх лет. Но в какой-то момент начали запускаться транспортные проекты, терминалы стали ставить в автобусах. Изменилась механика работы, выросла скорость. И, самое интересное, операции с этих терминалов агрегировались на один виртуальный терминал. Тот отчёт, который раньше работал с 5–7 тысячами транзакций, теперь начал подгружать 500 000–1 000 000 транзакций.
Что же произойдет с системой в этом случае? Представим, что сотрудник запустил выгрузку. Сервис загрузил 500 000 транзакций и начал их обрабатывать. Сотрудник оказался нетерпелив, в течение 20 минут он не дождался своего отчёта и решил перезапустить выгрузку. Сервис подгрузил еще 500 000 транзакций и в итоге мы получили график потребления памяти с двумя пиками на временном интервале в пол часа:
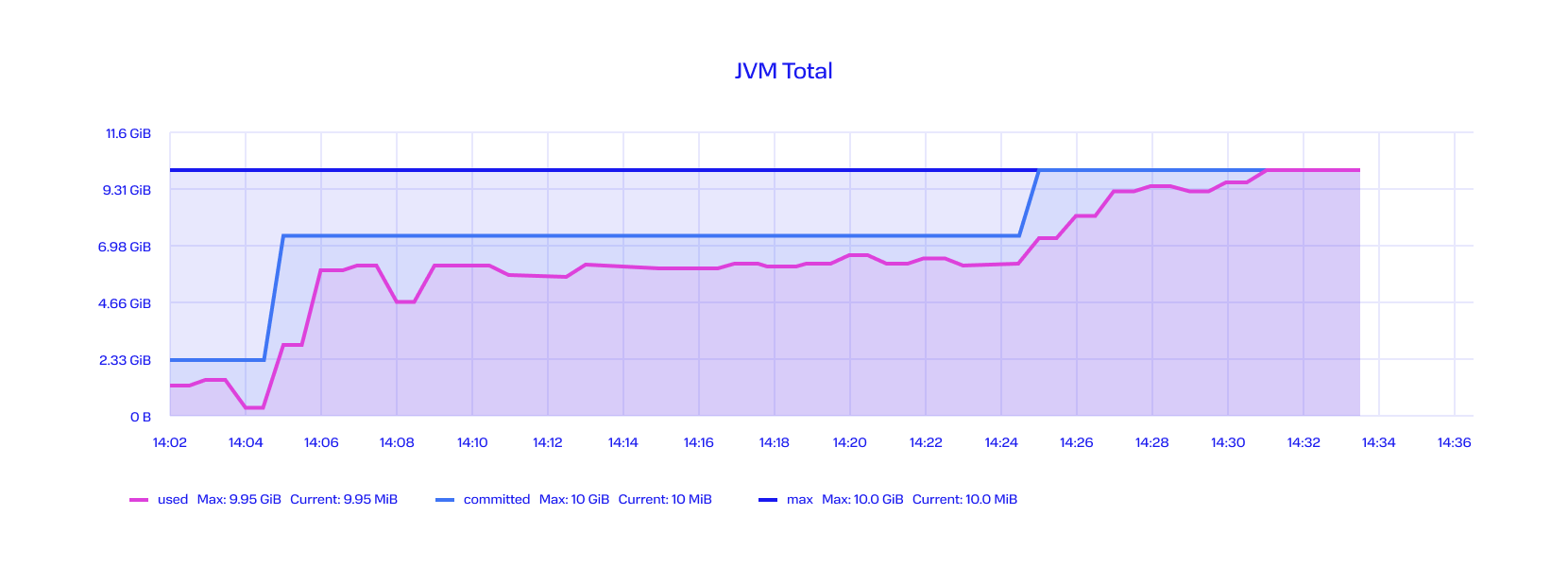
Как эту проблему решали? Заранее неизвестно, сколько операций на каком-то терминале будет обработано. При первой загрузке транзакций в базу им начали присваивать номер пачки, ввели понятие – батч, номер, который прикрепляли к каждой операции. Нумеровали транзакции по тысяче. Выгружать в отчеты начали блоками по одному батчу. Так получили некую фиксированную линейную сложность по памяти. Теперь нам не важно, сколько будет операций по какому терминалу. Мы всегда знаем, что их в памяти будет или до 1 000, или несколько батчей по 1 000.
База данных
Причин, по которым приложение может упасть из-за базы данных — множество:
Пул соединений
Если у вас любые две точки соединяются между собой, это обязательно пул. Чаще всего, пул соединений. Обычно он лимитирован и конечен. При спокойной работе сервис никогда в эти лимиты не упирается, но в высоконагруженных системах лимиты — наше всё.
Вот несколько советов как с этим жить:
Помните о существовании пула. Если вы работаете с Java и у вас SpringBoot, то под капотом будет JPA. А у JPA — Hibernate, у Hibernate, в свою очередь — Hikari. И вот Hikari – это и есть пул соединений, который мы настраиваем.
Многие знают, что можно настраивать максимальный размер пула, но не догадываются о том, что можно настраивать и таймаут на закрытие соединений: idle-timeout. Это позволит приложению закрывать соединения, когда они ему не требуются. Таким образом, когда вы разворачиваете 100 микросервисов, если по дефолту каждый из этих 100 микросервисов потребляет 10 соединений, вам понадобится 1 000 соединений, которые должна поддерживать база данных. Такой объем соединений слишком велик, и вы непременно столкнетесь с большими проблемами.
База данных
Причин, по которым приложение может упасть из-за базы данных — множество:
- Голодание пула соединений
- Партиционирование
- Медленные запросы (мимо индексов)
- Hibernate
- Высокая нагрузка на CPU
- Динамический план запроса
- Блокировки на апдейтах и дедлоки
- WAL
Пул соединений
Если у вас любые две точки соединяются между собой, это обязательно пул. Чаще всего, пул соединений. Обычно он лимитирован и конечен. При спокойной работе сервис никогда в эти лимиты не упирается, но в высоконагруженных системах лимиты — наше всё.
Вот несколько советов как с этим жить:
Помните о существовании пула. Если вы работаете с Java и у вас SpringBoot, то под капотом будет JPA. А у JPA — Hibernate, у Hibernate, в свою очередь — Hikari. И вот Hikari – это и есть пул соединений, который мы настраиваем.
Многие знают, что можно настраивать максимальный размер пула, но не догадываются о том, что можно настраивать и таймаут на закрытие соединений: idle-timeout. Это позволит приложению закрывать соединения, когда они ему не требуются. Таким образом, когда вы разворачиваете 100 микросервисов, если по дефолту каждый из этих 100 микросервисов потребляет 10 соединений, вам понадобится 1 000 соединений, которые должна поддерживать база данных. Такой объем соединений слишком велик, и вы непременно столкнетесь с большими проблемами.

Если же вы решили использовать такие настройки:

Тогда 100 приложений будут потреблять около 100-200 соединений (в среднем), и в такой конфигурации вполне можно комфортно существовать.
Когда приложение исчерпывает лимит соединений, ваши запросы встают в очередь. Эти моменты очень важно мониторить. Стандартный пул мониторинга Micrometer, Prometheus, Graphana позволяет строить прекрасные графики. Вот один из них:
Когда приложение исчерпывает лимит соединений, ваши запросы встают в очередь. Эти моменты очень важно мониторить. Стандартный пул мониторинга Micrometer, Prometheus, Graphana позволяет строить прекрасные графики. Вот один из них:
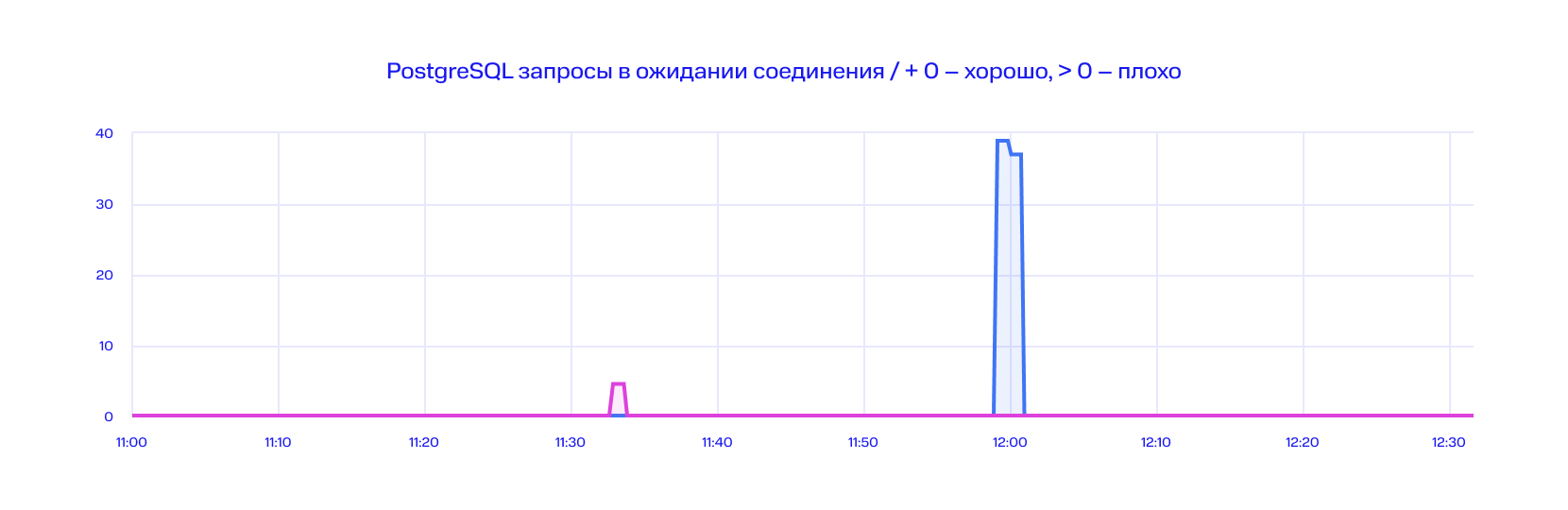
Всегда, когда у какого-либо из наших микросервисов заканчивается пул соединений и появляются запросы в ожидании соединения, мы увидим всплески на графиках. Иногда это нормально. Но в целом длительные ожидания запросов – это, по сути, деградация вашей системы. Поэтому нужно подключаться и анализировать.
Вот как это можно сделать:
Вот как это можно сделать:

Первая строка – это элемент конфигурации приложения, который позволяет сообщить базе данных имя вашего приложения, это имя вы будете видеть во всех запросах и статистиках, которые снимаете с базы.
Второе – это запрос из таблицы pg_stat_activity, если мы говорим про Postgresql. Это часто наиболее простой способ, понять, что у вас не так. Если вы видите деградацию базы банных, сделайте запрос на просмотр текущих активных сессий. Так вы увидите, какие запросы и микросервисы эти соединения расходуют. А дальше подключаете либо DBA, либо сами начинаете исследовать, в чем именно корень проблемы.
Конфигурация
Кроме того, проблемы БД могут быть конфигурационными. В нашем случае в highload-системе база данных — живой организм. Она сама думает, принимает решение, потому что в ней есть анализатор, планировщик. И подсказывать ему можно только сбором статистики.
Поэтому бывает проблема, что у вас всё работает прекрасно, нет апдейтов, и в какой-то момент Postgresql меняет планы запросов. После чего всё начинает работать жутко медленно, а вы не понимаете, что происходит.
В таком случае обычно достаточно прибежать и запустить на таблицу запрос analyze, и только после этого Postgresql такой: «Ладно, был не прав, возвращаюсь к нормальной работе».
Также в некоторых ситуациях нам помогала опция force generic plan:
Второе – это запрос из таблицы pg_stat_activity, если мы говорим про Postgresql. Это часто наиболее простой способ, понять, что у вас не так. Если вы видите деградацию базы банных, сделайте запрос на просмотр текущих активных сессий. Так вы увидите, какие запросы и микросервисы эти соединения расходуют. А дальше подключаете либо DBA, либо сами начинаете исследовать, в чем именно корень проблемы.
Конфигурация
Кроме того, проблемы БД могут быть конфигурационными. В нашем случае в highload-системе база данных — живой организм. Она сама думает, принимает решение, потому что в ней есть анализатор, планировщик. И подсказывать ему можно только сбором статистики.
Поэтому бывает проблема, что у вас всё работает прекрасно, нет апдейтов, и в какой-то момент Postgresql меняет планы запросов. После чего всё начинает работать жутко медленно, а вы не понимаете, что происходит.
В таком случае обычно достаточно прибежать и запустить на таблицу запрос analyze, и только после этого Postgresql такой: «Ладно, был не прав, возвращаюсь к нормальной работе».
Также в некоторых ситуациях нам помогала опция force generic plan:

Но это не серебряная пуля.
Отчеты
Как разработчикам, так и DBA полезно выгружать и уметь читать отчёты по производительности БД. Раньше я всегда думал, что долгие запросы приносят проблемы, быстрые запросы проблем не приносят. Поэтому когда я видел долгий выполняющийся запрос, то в случае каких-то проблем считал его виновным.
Но вот вам такой запрос:
Отчеты
Как разработчикам, так и DBA полезно выгружать и уметь читать отчёты по производительности БД. Раньше я всегда думал, что долгие запросы приносят проблемы, быстрые запросы проблем не приносят. Поэтому когда я видел долгий выполняющийся запрос, то в случае каких-то проблем считал его виновным.
Но вот вам такой запрос:

Этот запрос с виду несложный. Но в нём есть интересная конструкция distinct on. Она сделана, чтобы, используя мозги Posrgresql, вытащить сразу все необходимые данные, которые нам нужны, не прибегая к обработке в коде.
Я был удивлен, когда по отчету производительности увидел, что такой запрос выполнялся быстро, за миллисекунды, но создавал, по сравнению с остальными запросами, сумасшедшую нагрузку на ЦПУ, примерно 60%.
Мы его с лёгкостью переделали, заменили на 2 простых запроса, добавили обработку в коде, и наши проблемы ушли. Но сам факт, что такое возможно, для меня стал интересным сюрпризом.
ORM
Такие ORM, как Hibernate, разрабатывают для масс-маркета, и когда ваша нагрузка уникальная и серьезная, вы можете обнаружить забавные ситуации.
Например, когда мы смотрели запросы Хибера профилировщиком, обнаружили, что перед каждым Insert он делает Select. Это нужно, чтобы понять, есть ли в базе эта запись, и действительно ли нужно делать Insert, или достаточно заменить insert командой update. Наверное, это не то, чего вы действительно хотите, ведь в этом случае приложение делает два запроса вместо одного, и время значительно деградирует.
Мы столкнулись с ещё одной очень хитрой проблемой: наш любимый Хибернейт кэширует планы запросов. У нас они выглядят так: обновляем или селектим какие-то данные, в них указываем ключевое выражение in и перечисляем идентификаторы. Причём этих идентификаторов у нас не 5 или 4, как на слайде, а 1 000 вариаций.
Я был удивлен, когда по отчету производительности увидел, что такой запрос выполнялся быстро, за миллисекунды, но создавал, по сравнению с остальными запросами, сумасшедшую нагрузку на ЦПУ, примерно 60%.
Мы его с лёгкостью переделали, заменили на 2 простых запроса, добавили обработку в коде, и наши проблемы ушли. Но сам факт, что такое возможно, для меня стал интересным сюрпризом.
ORM
Такие ORM, как Hibernate, разрабатывают для масс-маркета, и когда ваша нагрузка уникальная и серьезная, вы можете обнаружить забавные ситуации.
Например, когда мы смотрели запросы Хибера профилировщиком, обнаружили, что перед каждым Insert он делает Select. Это нужно, чтобы понять, есть ли в базе эта запись, и действительно ли нужно делать Insert, или достаточно заменить insert командой update. Наверное, это не то, чего вы действительно хотите, ведь в этом случае приложение делает два запроса вместо одного, и время значительно деградирует.
Мы столкнулись с ещё одной очень хитрой проблемой: наш любимый Хибернейт кэширует планы запросов. У нас они выглядят так: обновляем или селектим какие-то данные, в них указываем ключевое выражение in и перечисляем идентификаторы. Причём этих идентификаторов у нас не 5 или 4, как на слайде, а 1 000 вариаций.

Когда мы проинструктировали наше сопровождение вовремя сделать дамп памяти, то обнаружили, что вся память была забита этими кэшированными планами запросов. Хибернейт цеплял туда дополнительные модели и вспомогательные данные. В результате, один план мог занимать около 1-3 мегабайт.
На каждый такой in было около 2 500 этих планов. Есть простейшая опция in clause parameter padding, которая решает конкретно эту проблему. Благодаря ей планы начинают кэшироваться по степени двойки. А промежуточные планы не сохраняются.
На каждый такой in было около 2 500 этих планов. Есть простейшая опция in clause parameter padding, которая решает конкретно эту проблему. Благодаря ей планы начинают кэшироваться по степени двойки. А промежуточные планы не сохраняются.

Дополнительно
Причем, когда происходит такой обрыв, прикладное ПО ничего об этом не знает, оно продолжает работать и использовать соединение. Ошибки, которые возникают в результате использования “битого” соединения, крайне непонятные и ужасно выглядят. Обычно все их пугаются.
Мы используем Project Reactor, и пул TCP соединений веб-клиента. Его можно настроить так, чтобы бездействующие более чем полчаса соединения автоматически закрывались самим приложением, а не Firewall.
- Если вставляете много данных, то делайте это батчами. Проводите профилактику вашей базы данных, заботьтесь о ней как о живом организме.
- Используйте, при необходимости, частичные индексы. Их называют по-разному: частичные, условные или предикатные. У них довольно простая реализация: они не требует много места на жёстком диске, но очень помогает ускорить процессы.
- И, конечно, самый лучший запрос в базу — тот, который не был сделан вовсе. Поэтому если у вас есть справочники с редко меняющимися данными, обязательно их кэшируйте и не заставляйте вашу базу данных выполнять лишние запросы.
TCP
Проблемы здесь случаются редко, и их легко решить железом. Простой пример: у Firewall есть такая особенность — обрывать коннекты, которые висят и ничего не делают на протяжении какого-то времени.Причем, когда происходит такой обрыв, прикладное ПО ничего об этом не знает, оно продолжает работать и использовать соединение. Ошибки, которые возникают в результате использования “битого” соединения, крайне непонятные и ужасно выглядят. Обычно все их пугаются.
Мы используем Project Reactor, и пул TCP соединений веб-клиента. Его можно настроить так, чтобы бездействующие более чем полчаса соединения автоматически закрывались самим приложением, а не Firewall.

Еще ситуация – у Project Reactor под капотом нет краёв, там — буферы, лимитированные количеством ядер и умноженные на 256. Также в системе есть файловые дескрипторы. Например, TCP-соединение – это файловый дескриптор. Их количество в системе ограничено как на процесс, так и на систему в целом.
У нас была забавная ситуация. Выкатили тестовый сервис, который начал порождать тысячи ТСР-соединений, одновременно делая запросы в другие сервисы. Тем самым превысил количество файловых дескрипторов вместе с другими сервисами на систему в целом. В результате начал отказывать софт на виртуалке. Первым по канонам отказал SSH, и мы потеряли доступ к серверу. Пришлось подключаться через систему виртуализации для того, чтобы этот доступ вернуть.
Таймауты
Многие это знают, но вдруг нет. Если у вас есть несколько сервисов, которые последовательно друг за другом обращаются к системе, то стоит выстроить таймауты «лесенкой». Тогда в случае крайнего таймаута, последнего звена, вы получите постепенный красивый отказ. Каждый сервис корректно среагирует и сохранит своим обработчиком какие-то данные, которые в результате таймаута зафиксируют ошибку.
У нас была забавная ситуация. Выкатили тестовый сервис, который начал порождать тысячи ТСР-соединений, одновременно делая запросы в другие сервисы. Тем самым превысил количество файловых дескрипторов вместе с другими сервисами на систему в целом. В результате начал отказывать софт на виртуалке. Первым по канонам отказал SSH, и мы потеряли доступ к серверу. Пришлось подключаться через систему виртуализации для того, чтобы этот доступ вернуть.
Таймауты
Многие это знают, но вдруг нет. Если у вас есть несколько сервисов, которые последовательно друг за другом обращаются к системе, то стоит выстроить таймауты «лесенкой». Тогда в случае крайнего таймаута, последнего звена, вы получите постепенный красивый отказ. Каждый сервис корректно среагирует и сохранит своим обработчиком какие-то данные, которые в результате таймаута зафиксируют ошибку.

Несмотря на то, что Project Reactor позволяет cancel-сигналами реагировать и на сброс соединения, я рекомендую использовать классический вариант настройки «лесенкой».
Кейс: HTTP Max Connections
Интересный инцидент произошел с системой быстрых платежей. Есть три системы: А — это платёжный хаб, В — промежуточная система и С — внешняя система.
Кейс: HTTP Max Connections
Интересный инцидент произошел с системой быстрых платежей. Есть три системы: А — это платёжный хаб, В — промежуточная система и С — внешняя система.
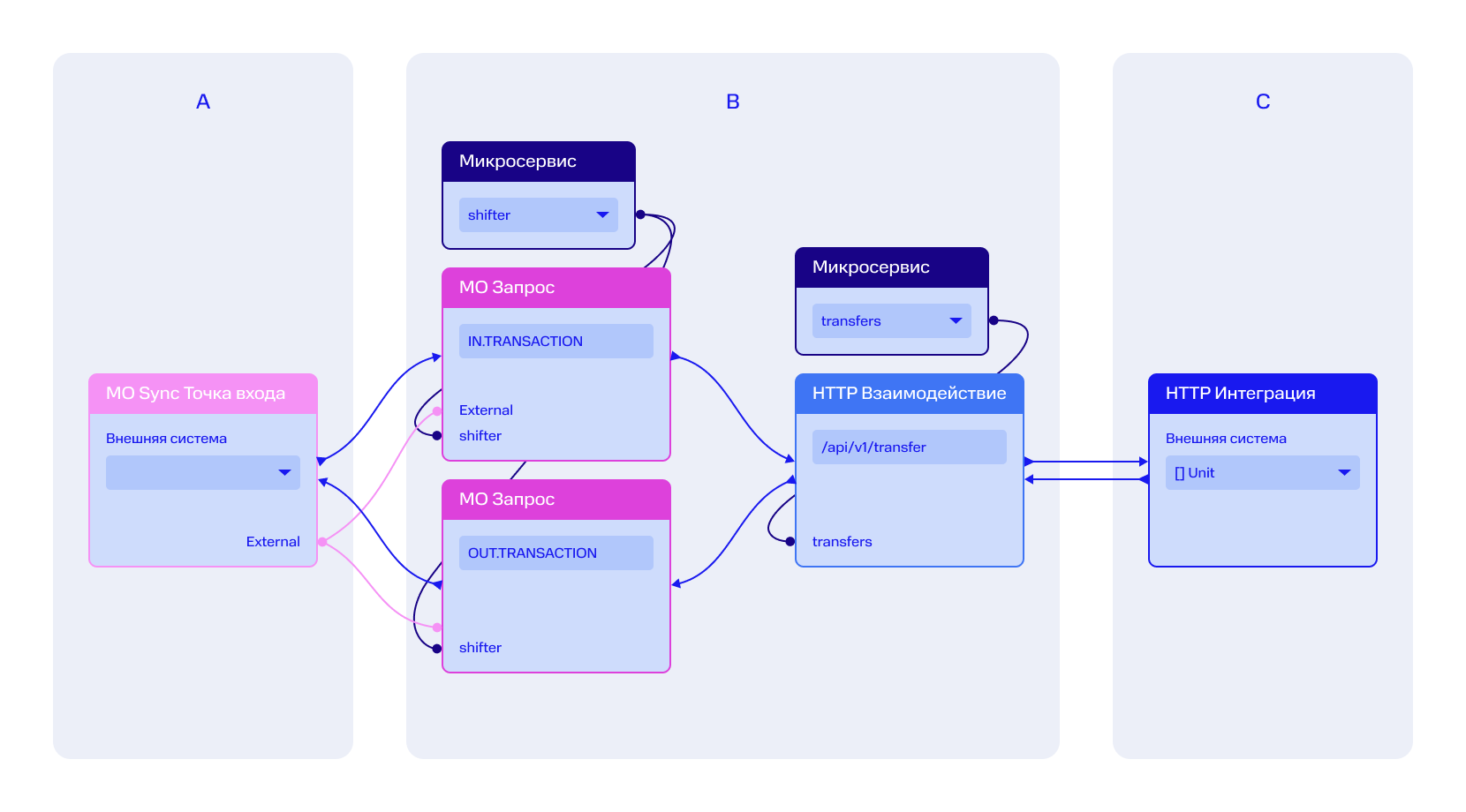
Мы посылали запросы из системы А в систему В, и всё было прекрасно. SLA у нас был 5 секунд. В какой-то момент время ответа стало увеличиваться. С 1 секунды мы постепенно получали 1,5 секунды, потом 2. Потом стали возникать таймауты. У нас на таймауты срабатывал circuit breaker: мы замыкали соединение, переставали делать запросы, давали промежуточной системе отдышаться в течение минуты, возобновляли трафик, и всё налаживалось. Но через какое-то врем снова начинало увеличиваться время ответа.
Мы задали вопрос в систему В о том, что происходит. Оказалось, там всё в порядке. В системе С — тоже У всех всё в порядке, но проблема есть. Если посмотреть на устройство системы В, то красными прямоугольниками обозначены очереди ответов, куда приходил трафик, а зелёный прямоугольник — НТТР-взаимодействие. Сервис там принимал запрос в очереди и дальше отправлял его по НТТР. Мы вскрыли этот сервис и обнаружили там классическую реализацию MVC, которая вычитывает сообщение из очереди, запускает поток, перенаправляет трафик в НТТР, дожидается ответа, затем отвечает обратно очередь.
По логам мы наблюдали очень странную ситуацию. Время ответа от системы С достигало 15-20 секунд, хотя таймаут стоит на 3-4. Сделали thread dump, обнаружили следующее: около сотни потоков в этом сервисе висели в ожидании соединения из пула. Когда начали разбираться, оказалось, что у SpringBoot приложения под капотом RestTemplate. А у него, в свою очередь, под капотом — Apache веб-клиент. Каково же было наше удивление, когда у Apache веб-клиента лимит пула соединений составил всего 10. Этот сервис работал годами раньше, и нагрузка не достигала пика, то есть система С просто немного замедлила время ответа. Из-за этого соединения всё больше и больше начинали накапливаться.
Эта проблема опасна ещё и тем, что, когда с ней сталкиваются, то часто заливают железом, поднимают новые инстансы и серверы. В целом это закроет проблему, но на самом деле для решения достаточно добавить одну опцию:
http-max-connections=100
Мониторинг соединений
Посмотрев на эту проблему в системе В, в системе А мы тоже сразу же начали пилить мониторинг на количество TCP-соединений у наших веб-клиентов. Обнаружили, что Project Reactor по умолчанию использует клиента, у которого 500 соединений на каждый end point.
Если вы подключаетесь по 10 разным endpoint’ам, у вас будет, грубо говоря, 10 пулов по 500 соединений (общий лимит 1000).
С помощью графиков мы можем отслеживать, когда размер пула приближается к 500. Для нас это звоночек о том, что нужно либо сокращать время таймаута, либо масштабироваться.
Выводы
Мы задали вопрос в систему В о том, что происходит. Оказалось, там всё в порядке. В системе С — тоже У всех всё в порядке, но проблема есть. Если посмотреть на устройство системы В, то красными прямоугольниками обозначены очереди ответов, куда приходил трафик, а зелёный прямоугольник — НТТР-взаимодействие. Сервис там принимал запрос в очереди и дальше отправлял его по НТТР. Мы вскрыли этот сервис и обнаружили там классическую реализацию MVC, которая вычитывает сообщение из очереди, запускает поток, перенаправляет трафик в НТТР, дожидается ответа, затем отвечает обратно очередь.
По логам мы наблюдали очень странную ситуацию. Время ответа от системы С достигало 15-20 секунд, хотя таймаут стоит на 3-4. Сделали thread dump, обнаружили следующее: около сотни потоков в этом сервисе висели в ожидании соединения из пула. Когда начали разбираться, оказалось, что у SpringBoot приложения под капотом RestTemplate. А у него, в свою очередь, под капотом — Apache веб-клиент. Каково же было наше удивление, когда у Apache веб-клиента лимит пула соединений составил всего 10. Этот сервис работал годами раньше, и нагрузка не достигала пика, то есть система С просто немного замедлила время ответа. Из-за этого соединения всё больше и больше начинали накапливаться.
Эта проблема опасна ещё и тем, что, когда с ней сталкиваются, то часто заливают железом, поднимают новые инстансы и серверы. В целом это закроет проблему, но на самом деле для решения достаточно добавить одну опцию:
http-max-connections=100
Мониторинг соединений
Посмотрев на эту проблему в системе В, в системе А мы тоже сразу же начали пилить мониторинг на количество TCP-соединений у наших веб-клиентов. Обнаружили, что Project Reactor по умолчанию использует клиента, у которого 500 соединений на каждый end point.
Если вы подключаетесь по 10 разным endpoint’ам, у вас будет, грубо говоря, 10 пулов по 500 соединений (общий лимит 1000).
С помощью графиков мы можем отслеживать, когда размер пула приближается к 500. Для нас это звоночек о том, что нужно либо сокращать время таймаута, либо масштабироваться.
Выводы
- Выбирайте правильные HTTP-клиенты (или настраивайте неправильные =).
- Обязательно, до того как вы столкнетесь с проблемами, узнавайте заранее про размеры своих пулов. Это не тривиальная ситуация: возможно, придётся копнуть в код поглубже.
- Настраивайте таймауты правильно.
- Вовремя принимайте решение о масштабировании. И здесь, конечно, также действует правило, как и с базами данных: лучший запрос по HTTP — это запрос, который не был сделан.
- Кэшируйте веб-запросы.








