

Раньше нагрузочное тестирование проводилось сервисной командой на последнем этапе. Это дорого и долго: дорогой стенд, который надо собрать, продлайк, много железа, много интеграций, дорогие и редкие на рынке инженеры с уникальными знаниями вроде JMeter, LoadRunner, Gatling и так далее.
Как обычно выглядит схема нагрузочного тестирования:
- Спроектировали.
- Разработали.
- Протестировали.
- Начинаем проверять работающий продукт на перформанс.
- Традиционный итог — перформанса не хватает, надо всё переделывать.

Классический водопад — это долго, дорого, и вообще он морально устарел. Сейчас нам важно минимизировать время от идеи до реализации и выхода на рынок, и для этого подходит концепция shift-left. То есть мы смещаемся влево по таймлайну и начинаем тестирование АСАП.
Мы решили поменять процессы, например, уйти от релизов и дать командам независимо внедряться. Для этого должны быть весь набор практик и экспертиза.
Но нам нужно научить их исследовать производительность. Сейчас они решают проблемы в этой области, но поиск «бутылочных горлышек», которые мы обнаруживаем в ходе тестирования, сложнее. «Бутылочные горлышки» — это неоптимальные конфигурация сервисов и код, нехватка ресурсов, потоков, памяти, неэффективное обращение к базам данных.
Если обучить разработчиков этим навыкам, то процесс значительно ускорится, ведь во многих компаниях разработчиков гораздо больше, чем специалистов по нагрузочному тестированию. Старая схема может занимать недели: продукт выйдет, его протестируют, а потом к разработчикам вернутся с обратной связью, что где-то есть проблемы с производительностью. Если же разработчик умеет сам искать ошибки — он практически мгновенно после внесения изменений в код может узнать, стало хуже или нет. Именно для этого мы перенесли нагрузочное тестирование влево на стадию юнит-тестов.
Поясню: в Java любой метод, написанный изначально, не является ни юнит-тестом, ни бенчмарком. Методы становятся ими за счёт аннотаций. Так можно превратить любой юнит-тест в бенчмарк-тест. Это небольшие правки в коде.
Чтобы сделать первый простой тест, необходимо:
1. Обеспечить наличие в проекте пяти библиотек JMH и одного плагина для Gradle. Версия Gradle в проекте требуется не ниже 6.8.
2. Добавить в build.gradle зависимости и этап сборки с названием JMH c минимальными настройками.
Зависимости
Мы решили поменять процессы, например, уйти от релизов и дать командам независимо внедряться. Для этого должны быть весь набор практик и экспертиза.
К чему идем
На одного инженера с уникальными скиллами у нас более 25 разработчиков, и мы хотим включить их в процесс нагрузочного тестирования.Но нам нужно научить их исследовать производительность. Сейчас они решают проблемы в этой области, но поиск «бутылочных горлышек», которые мы обнаруживаем в ходе тестирования, сложнее. «Бутылочные горлышки» — это неоптимальные конфигурация сервисов и код, нехватка ресурсов, потоков, памяти, неэффективное обращение к базам данных.
Если обучить разработчиков этим навыкам, то процесс значительно ускорится, ведь во многих компаниях разработчиков гораздо больше, чем специалистов по нагрузочному тестированию. Старая схема может занимать недели: продукт выйдет, его протестируют, а потом к разработчикам вернутся с обратной связью, что где-то есть проблемы с производительностью. Если же разработчик умеет сам искать ошибки — он практически мгновенно после внесения изменений в код может узнать, стало хуже или нет. Именно для этого мы перенесли нагрузочное тестирование влево на стадию юнит-тестов.
Тестировать только тот код, который менялся
Мы изучили, какие типы тестов могут делать разработчики, потом поискали и нашли не очень новое, но малоизвестное решение. Это JMH-библиотека от Open JDK. Она позволяет исследовать перформанс Java-приложений на уровне кода так же, как и юнит-тесты. И мы предложили разработчикам использовать эту библиотеку, поскольку порог вхождения в неё достаточно низкий. Это тот же Junit и low-code за счёт небольшого набора аннотаций.Поясню: в Java любой метод, написанный изначально, не является ни юнит-тестом, ни бенчмарком. Методы становятся ими за счёт аннотаций. Так можно превратить любой юнит-тест в бенчмарк-тест. Это небольшие правки в коде.
Чтобы сделать первый простой тест, необходимо:
1. Обеспечить наличие в проекте пяти библиотек JMH и одного плагина для Gradle. Версия Gradle в проекте требуется не ниже 6.8.
2. Добавить в build.gradle зависимости и этап сборки с названием JMH c минимальными настройками.
Зависимости

3. Выбрать класс и несколько методов, которые хотим протестировать. Мы сделаем тест производительности из JUnit-теста, который покрывает ключевые методы. Класс теста и тестируемые методы этого класса должны быть public.
Пример, как сделать benchmark из JUnit
Пример, как сделать benchmark из JUnit

4. Запуск сборки:
Вариант локально запускать так:
gradle clean jmh
Вариант CICD. В дальнейшем вам потребуется джоб в CI\CD.
5. Анализ результата. Инструмент выводит результаты в нескольких форматах (raw, csv, json). Текстовый отчёт можно смотреть в логе, а также есть возможность формировать графический отчёт.
Таким образом, мы добавляем пять библиотек в зависимости, находим методы, которые нам уже подходят, скажем, это юнит-тесты, и добавляем туда аннотацию — собака бенчмарк. При сборке они начинают запускаться автоматически, и по ним формируется отчёт.
Существует классическая модель, когда уже собранные артефакт, сервис или система устанавливаются на тестовый стенд для нагрузочного тестирования, и с помощью специализированных инструментов проводится исследование производительности — это инженерная нагрузка. Она дорогая: подстенд должен быть мощным и сопоставимым с продакшеном. А ещё она медленная.
А вот этот подход с библиотекой и конвертацией юнит-тестов в бенчмарк-тесты позволяет интегрировать тестирование в конвейер сборки. Тесты содержатся внутри самого предложения, являясь исходным кодом. Когда приложение собирается на конвейере в CI/CD, эти тесты автоматически запускаются в том же окружении.
Это намного быстрее и эффективнее, чем использовать выделенный стенд со специализированными инструментами. Вам нужен только рабочий ноутбук или агент сборочного конвейера. У разработчика есть сборщик исходного кода, в котором находятся жизненные циклы или фазы этой сборки. Там есть фаза билда — для сборки приложений, а есть фаза теста — для, вы не поверите, запуска тестов. Фаза теста выполняет методы, которые помечены как бенчмарк, и генерирует отчёт с результатами.
Эта фаза выполняется автоматически при сборке сервиса в конвейере, поэтому разработчику не нужно ничего, кроме сборочного агента. Просто задать в IDE команду — ловкость рук и никаких стендов!
Таким образом, если нагрузочное тестирование — это дорого и долго, то подход с библиотекой и конвертацией юнит-тестов в бенчмарк-тесты дешевле и быстрее.
Разумеется, есть разница в использовании ноутбука и стенда. Но нас не очень часто интересует, какой максимум в секунду может выполнить конкретный метод, — тысячу или две. Нам гораздо важнее понять, улучшилась или ухудшилась производительность после внесённых изменений.
Проведя два теста — до и после — и сравнив результаты, можно понять, стало лучше или хуже. Выяснить это и есть наша цель.
Эту проверку мы настраиваем в своём пайплайне и выставляем трешхолды. Так сборка может быть зафейлена, и плохой код не уйдёт в продакшен.
Выставляя трешхолды, мы замеряем, насколько изменилось время при изменениях кода. Если оно увеличилось на 25 %, то тест не пройден. При этом нормальная погрешность — 20 %, так как производительность зависит от очень многих факторов.
Если объяснять конкретнее: мы повторяем вызов одного и того же метода тысячу раз, замеряем среднее время выполнения — это и есть то значение, от которого мы отталкиваемся. Для нас в этом подходе важно не абсолютное значение, а изменение по сравнению с предыдущей версией кода.
От чего зависит погрешность измерения: текущая загруженность машины, какие процессы параллельно запущены и т. д. То есть отклонение на 2 % нельзя считать доказательством ухудшения производительности. Скорее всего, это погрешность. Мы проводили серию тестов на одной и той же версии кода, и погрешности инфраструктуры и оборудования составляли не более 20 %, поэтому трешхолд мы поставили 25 %. Это порог, при котором мы приостанавливаем сборку и начинаем анализировать причины ухудшения.
При внедрении любых подобных инструментов часто говорят: «Ну, классно! Но как нам это использовать? Там неудобно и не автоматизировано».
На самом деле существует множество плагинов к TeamCity, к Jenkins. Есть автоматизированные репорты, где можно встраивать в пайплайн свой отчёт. Он всегда есть в артефактах сборки. Можно две сборки сравнить между собой и узнать, как меняется перформанс.
Ещё есть функция профилирования и инструментации. Благодаря ей сразу можно узнать:
Идея функции — в возможности подключения специальных инструментов к приложению для проверки его поведения под нагрузкой. Сам инструмент, помимо того что создаёт нагрузку на код, формирует простой короткий отчёт, в котором перечислены наиболее затратные методы и другие данные, например, какие методы были в работе дольше всего. И если что-то ухудшается — мы примерно понимаем, что пошло не так.
Проблемы производительности возникают и при блокировках. Поэтому в этом же отчёте после тестирования инструмент приводит серию блокировок. Здесь важны опять же не столько абсолютные значения, сколько стабильное время работы методов после изменения кода.
Вот как выглядит отчёт. Он позволяет измерить метрики у целого списка различных инструментов, в том числе память — тоже.
1. В текстовом логе результаты выглядят так:
Результат stack
Вариант локально запускать так:
gradle clean jmh
Вариант CICD. В дальнейшем вам потребуется джоб в CI\CD.
5. Анализ результата. Инструмент выводит результаты в нескольких форматах (raw, csv, json). Текстовый отчёт можно смотреть в логе, а также есть возможность формировать графический отчёт.
Таким образом, мы добавляем пять библиотек в зависимости, находим методы, которые нам уже подходят, скажем, это юнит-тесты, и добавляем туда аннотацию — собака бенчмарк. При сборке они начинают запускаться автоматически, и по ним формируется отчёт.
Существует классическая модель, когда уже собранные артефакт, сервис или система устанавливаются на тестовый стенд для нагрузочного тестирования, и с помощью специализированных инструментов проводится исследование производительности — это инженерная нагрузка. Она дорогая: подстенд должен быть мощным и сопоставимым с продакшеном. А ещё она медленная.
А вот этот подход с библиотекой и конвертацией юнит-тестов в бенчмарк-тесты позволяет интегрировать тестирование в конвейер сборки. Тесты содержатся внутри самого предложения, являясь исходным кодом. Когда приложение собирается на конвейере в CI/CD, эти тесты автоматически запускаются в том же окружении.
Это намного быстрее и эффективнее, чем использовать выделенный стенд со специализированными инструментами. Вам нужен только рабочий ноутбук или агент сборочного конвейера. У разработчика есть сборщик исходного кода, в котором находятся жизненные циклы или фазы этой сборки. Там есть фаза билда — для сборки приложений, а есть фаза теста — для, вы не поверите, запуска тестов. Фаза теста выполняет методы, которые помечены как бенчмарк, и генерирует отчёт с результатами.
Эта фаза выполняется автоматически при сборке сервиса в конвейере, поэтому разработчику не нужно ничего, кроме сборочного агента. Просто задать в IDE команду — ловкость рук и никаких стендов!
Таким образом, если нагрузочное тестирование — это дорого и долго, то подход с библиотекой и конвертацией юнит-тестов в бенчмарк-тесты дешевле и быстрее.
Разумеется, есть разница в использовании ноутбука и стенда. Но нас не очень часто интересует, какой максимум в секунду может выполнить конкретный метод, — тысячу или две. Нам гораздо важнее понять, улучшилась или ухудшилась производительность после внесённых изменений.
Проведя два теста — до и после — и сравнив результаты, можно понять, стало лучше или хуже. Выяснить это и есть наша цель.
Эту проверку мы настраиваем в своём пайплайне и выставляем трешхолды. Так сборка может быть зафейлена, и плохой код не уйдёт в продакшен.
Выставляя трешхолды, мы замеряем, насколько изменилось время при изменениях кода. Если оно увеличилось на 25 %, то тест не пройден. При этом нормальная погрешность — 20 %, так как производительность зависит от очень многих факторов.
Если объяснять конкретнее: мы повторяем вызов одного и того же метода тысячу раз, замеряем среднее время выполнения — это и есть то значение, от которого мы отталкиваемся. Для нас в этом подходе важно не абсолютное значение, а изменение по сравнению с предыдущей версией кода.
От чего зависит погрешность измерения: текущая загруженность машины, какие процессы параллельно запущены и т. д. То есть отклонение на 2 % нельзя считать доказательством ухудшения производительности. Скорее всего, это погрешность. Мы проводили серию тестов на одной и той же версии кода, и погрешности инфраструктуры и оборудования составляли не более 20 %, поэтому трешхолд мы поставили 25 %. Это порог, при котором мы приостанавливаем сборку и начинаем анализировать причины ухудшения.
При внедрении любых подобных инструментов часто говорят: «Ну, классно! Но как нам это использовать? Там неудобно и не автоматизировано».
На самом деле существует множество плагинов к TeamCity, к Jenkins. Есть автоматизированные репорты, где можно встраивать в пайплайн свой отчёт. Он всегда есть в артефактах сборки. Можно две сборки сравнить между собой и узнать, как меняется перформанс.
Ещё есть функция профилирования и инструментации. Благодаря ей сразу можно узнать:
- Какие методы тормозят.
- Где и как ведут себя память и потоки.
Идея функции — в возможности подключения специальных инструментов к приложению для проверки его поведения под нагрузкой. Сам инструмент, помимо того что создаёт нагрузку на код, формирует простой короткий отчёт, в котором перечислены наиболее затратные методы и другие данные, например, какие методы были в работе дольше всего. И если что-то ухудшается — мы примерно понимаем, что пошло не так.
Проблемы производительности возникают и при блокировках. Поэтому в этом же отчёте после тестирования инструмент приводит серию блокировок. Здесь важны опять же не столько абсолютные значения, сколько стабильное время работы методов после изменения кода.
Вот как выглядит отчёт. Он позволяет измерить метрики у целого списка различных инструментов, в том числе память — тоже.
1. В текстовом логе результаты выглядят так:
Результат stack

2. При сборке в TeamCity будет формироваться отчёт, примерный его вид — ниже.
Результаты одного теста:
Результаты одного теста:
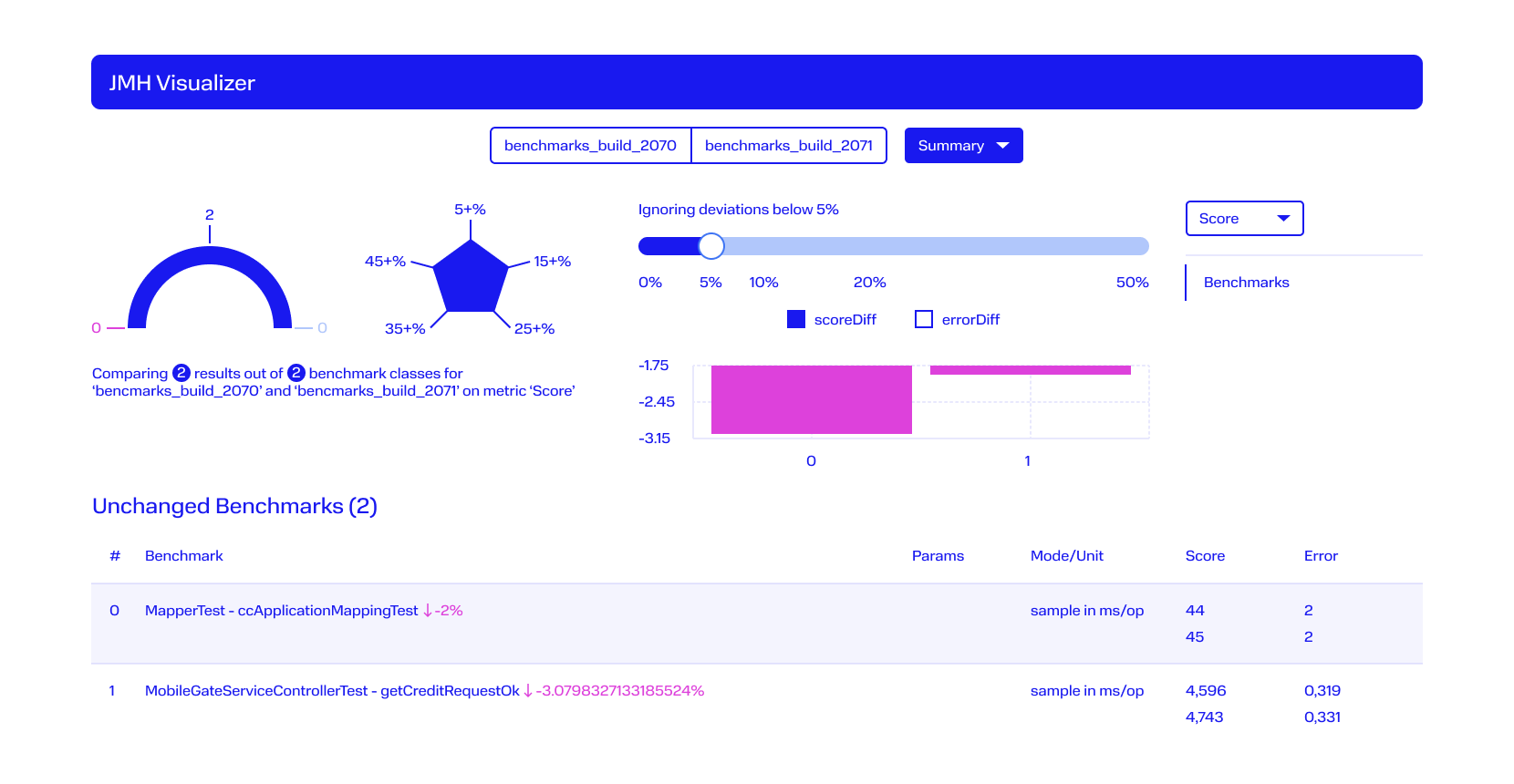
Пример сравнения двух тестов:
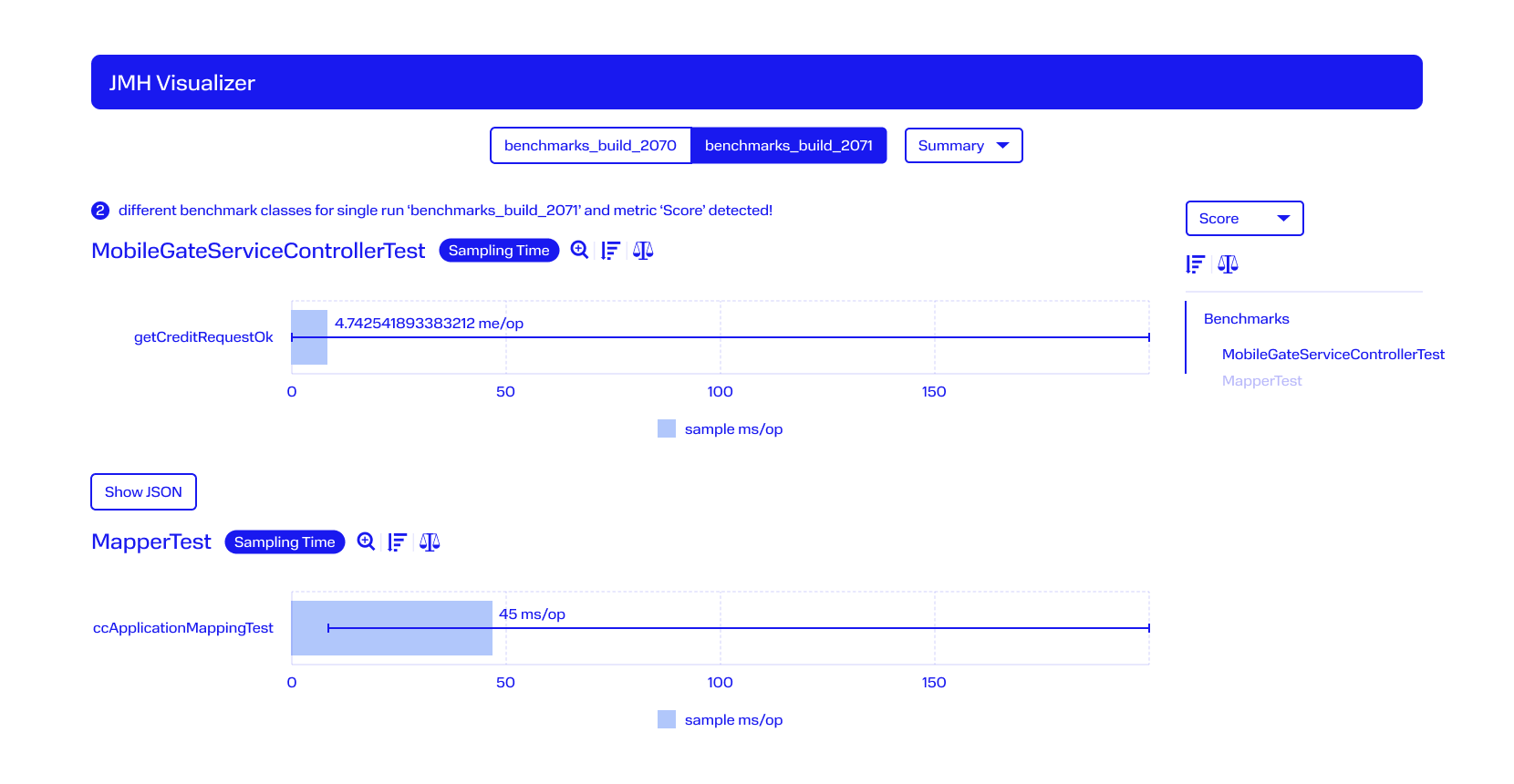
Скорость тестирования, конечно, сильно зависит от сервиса, который проверяется, и от того, насколько он покрыт тестами. Если методов и классов очень много, то тестирование, скорее всего, будет длительным. Сборка может идти и несколько часов, если на неё повесить очень много долгих тестов.
Мы, конечно, не тестируем всё подряд. Мы сфокусировались на тестировании кода, который был изменён. Для этого написали в нашем конвейере небольшую функцию, которая определяет изменённый код и запускает тесты только для этих методов и классов. Это позволяет в разы сократить время сборки: сразу понятно, что поменялось и в какую сторону, а это очень удобно.
А ещё тесты можно группировать.
Группировка тестов
При группировке тестов мы помечаем некоторые методы одной группой. Например, это будет группа работы с клиентом — тогда в неё объединятся методы создания, удаления и изменения клиента.
Для чего это нужно? Иногда просто чтение данных о клиенте или просто его изменение не вызывает проблем. Но когда методы пересекаются, возникают блокировки и проблемы производительности.
Соответственно, инструмент позволяет для таких критических участков объединить несколько тестов одной группы. Они будут запускаться параллельно, что позволит выявить проблемы, такие, как блокировки общих ресурсов или объектов, которые могут остаться незамеченными при запуске тестов по отдельности.
Например, вы заходите на сайт в первый раз, а я там уже зарегистрирован. В этот момент система создаёт ваш профиль и ищет мой. Обе эти операции — работа с клиентами. Если их объединить в группу тестов, то параллельный запуск сценариев с поиском, созданием и удалением клиентов может выявить такие проблемы, как блокировка таблицы справочника клиентов или отвалившийся поиск.
В общем, новый подход к тестам позволяет найти проблему с производительностью на ранних этапах сразу после изменения кода в автоматизированном режиме, встроив эту фазу в пайплайн сборки.
А без такого подхода процесс выглядит совершенно иначе: разработчик собирает приложение, передаёт специалистам по нагрузочному тестированию, которые его деплоят, пишут скрипты для имитации действий пользователя, проводят исследования и возвращаются к разработчикам с фидбэком.
То есть это история про движение влево и про практически моментальную обратную связь, которую разработчик получает в течение нескольких минут. Мы можем прогнать перформанс-тест за две минуты плюс две-три — на прогрев, и узнать, например, что новый код работает не хуже старого.
Мы, конечно, не тестируем всё подряд. Мы сфокусировались на тестировании кода, который был изменён. Для этого написали в нашем конвейере небольшую функцию, которая определяет изменённый код и запускает тесты только для этих методов и классов. Это позволяет в разы сократить время сборки: сразу понятно, что поменялось и в какую сторону, а это очень удобно.
А ещё тесты можно группировать.
Группировка тестов
При группировке тестов мы помечаем некоторые методы одной группой. Например, это будет группа работы с клиентом — тогда в неё объединятся методы создания, удаления и изменения клиента.
Для чего это нужно? Иногда просто чтение данных о клиенте или просто его изменение не вызывает проблем. Но когда методы пересекаются, возникают блокировки и проблемы производительности.
Соответственно, инструмент позволяет для таких критических участков объединить несколько тестов одной группы. Они будут запускаться параллельно, что позволит выявить проблемы, такие, как блокировки общих ресурсов или объектов, которые могут остаться незамеченными при запуске тестов по отдельности.
Например, вы заходите на сайт в первый раз, а я там уже зарегистрирован. В этот момент система создаёт ваш профиль и ищет мой. Обе эти операции — работа с клиентами. Если их объединить в группу тестов, то параллельный запуск сценариев с поиском, созданием и удалением клиентов может выявить такие проблемы, как блокировка таблицы справочника клиентов или отвалившийся поиск.
В общем, новый подход к тестам позволяет найти проблему с производительностью на ранних этапах сразу после изменения кода в автоматизированном режиме, встроив эту фазу в пайплайн сборки.
А без такого подхода процесс выглядит совершенно иначе: разработчик собирает приложение, передаёт специалистам по нагрузочному тестированию, которые его деплоят, пишут скрипты для имитации действий пользователя, проводят исследования и возвращаются к разработчикам с фидбэком.
То есть это история про движение влево и про практически моментальную обратную связь, которую разработчик получает в течение нескольких минут. Мы можем прогнать перформанс-тест за две минуты плюс две-три — на прогрев, и узнать, например, что новый код работает не хуже старого.








