.png)

Содержание:
Рост предсказательной аналитики
Предсказательная, или предиктивная, аналитика помогает прогнозировать важные для бизнеса показатели. Например, с какой вероятностью клиент согласится оформить финансовый продукт или где разместить новый офис, чтобы он приносил большую прибыль.Предиктивная аналитика тесно связана с data-driven-подходом, согласно которому компании принимают ключевые бизнес-решения на основе большого массива данных, или big data. Для этого их собирают из разных внутренних систем и внешних источников. Используя эти данные, специалисты по машинному обучению строят модели, чтобы найти закономерности и извлечь бизнес-ценность для компании.
В финтехе предиктивную аналитику внедряют, чтобы:
- Увеличить эффективность рекламных кампаний. Например, в Газпромбанке запущен маркетинговый оптимизатор, который предлагает, как распределять клиентов по каналам коммуникации в зависимости от продукта.

- Управлять рисками. Искусственный интеллект в состоянии определить сигналы в финансовом поведении клиента, которые указывают на возможные проблемы.
- Обнаруживать мошеннические транзакции в системах антифрода. На обучающей выборке модели учатся различать подозрительные операции и прогнозировать вероятность их совершения.
- Создавать персонализированные предложения. Каждый клиент пользуется финансовыми продуктами, которыми закрывает свои потребности. Например, одни берут кредиты на путешествия, другие — на ремонт. Машинное обучение помогает изучить интересы и потребности клиентов, чтобы предложить продукт, который им сейчас нужен.
- Делать коммуникацию с помощью голосовых помощников более эффективной и естественной. Благодаря предиктивной аналитике они учатся понимать, какая тональность и темп речи будут наиболее приятны и убедительны для собеседника.
Бизнес-подход к работе с данными
Как извлекать данные и каких принципов в работе с ними придерживаться, в каждой компании решают по-своему. Можно делать упор на моделировании и технической составляющей обработки данных, а можно сфокусироваться на бизнес-задачах, которые стоят перед компанией. При таком подходе используется стандарт CRISP-DM (Cross-Industry Standard Process for Data Mining).
Методология хоть и не новая, но не теряет популярности. Анализ поисковых запросов в Google за 2019–2020 годы показывает интерес к этой методологии: информацию о ней искали более 4 000 раз.
- Бизнес-анализ. Цели этого этапа — понять, какие требования ставит бизнес, что он хочет получить. Когда цели понятны, их можно переформулировать в контексте задач дата-сайентистов. Например, по какой метрике будет оцениваться результативность модели и что будет говорить о ее успешности.
- Анализ данных. На этом шаге команда собирает первоначальные данные и проверяет их качество.
- Подготовка данных. Этап включает отбор данных, исправление или удаление ошибок в наборах, интеграцию данных из нескольких источников.
- Моделирование. В зависимости от задачи специалисты выбирают несколько моделей, которые обучают на подготовленных данных.
- Оценка решений. Когда модель построена и протестирована, результат ее работы оценивается с точки зрения достижения бизнес-требований, которые были сформулированы еще на первом шаге.
- Внедрение. Если результат модели устраивает бизнес, то ее внедряют в прод.
Обработка данных в реальном времени
Предсказательная аналитика в основном опирается на исторические данные, которые собраны, например, за неделю, месяц и более. Но сейчас наблюдается тренд на использование данных, полученных в реальном времени. Исследование международного аналитического агентства Forrester Research показало, что такие данные в предиктивной аналитике планируют внедрить или уже используют 89% банков, представители которых участвовали в опросе.
Обработка потоковых данных в реальном времени помогает финтех-компаниям учитывать в общении с клиентом его текущее поведение. Например, человек, который никогда не интересовался кредитом на недвижимость, стал заходить в раздел «Ипотека» в банковском приложении. Раньше, чтобы бизнес учел это изменение в поведении и смог предложить клиенту актуальный продукт, должно было пройти время. А обработка потоковых данных позволяет увидеть это в моменте и применить для решения задач.
Real-time-данные в сочетании с предиктивной аналитикой помогают быстрее обнаружить и приостанавливать подозрительные транзакции. Алгоритмы машинного обучения выявляют неочевидные закономерности в поведении клиента. Чем быстрее получится обнаружить такие транзакции и проверить на мошенничество, тем эффективнее работает банк.

Аналитика правильных данных
Чтобы построить модель, результаты которой можно использовать на практике, нужны качественные данные. Согласно стандарту ISO 9000:2015, они должны быть:
-
Полными — когда данных достаточно, чтобы решить поставленную бизнес-задачу.
-
Достоверными — они не искажены и не содержат ошибки, например аномальные значения, которые возникли из-за сбоя в сервисе.
-
Точными — показывают нужный уровень детализации, например сколько транзакций совершается каждый час, а не каждый день.
-
Согласованными — в наборах данных, которые связаны между собой, нет противоречий. Если два клиента банка имеют одинаковый доход, владеют недвижимостью равной площади, то кредитный рейтинг у них должен быть одинаковым, а не разным.
-
Своевременными — данные доступны в нужный момент времени.
Поскольку массив данных, которые генерируют финтех-компании, большой, отобрать полезные данные под конкретную задачу непросто. Кроме того, среди внутренних данных может не оказаться нужных, потому что их не собирают. Например, компания хочет использовать в прогнозной модели стоимость квадратного метра в Москве за последние полгода. Своих данных по этому показателю у нее нет, поэтому надо приобрести их у другой организации. При этом важно, чтобы датасет был с правильными данными, которые легко обработать, интерпретировать и использовать в контуре компании.
Большие объемы данных позволяют выявлять всё более нетривиальные закономерности и на их основе делать более точные прогнозы. Но мир быстро меняется, внешние условия влияют на поведение пользователей и целые отрасли, что заставляет компании искать новый подход к управлению данными.
Простой доступ к нужному источнику данных
Компании хранят данные в нескольких источниках: часть может стекаться во внутреннее хранилище, другие разделены между базами разных отделов или облачными сервисами. Чтобы в любой момент использовать нужный датасет, у специалистов должен быть доступ ко всем источникам. Для управления данными, которые разбиты между несколькими хранилищами, разработали концепцию Data mesh.
В этой концепции разрозненные источники существуют сами по себе. Каждым хранилищем управляет своя команда, она же решает, какую data-архитектуру применить. Так легче обходить бюрократические сложности, которые бывают при централизованном хранении данных. Но в то же время команде придется обеспечить доступ к источнику, если он потребуется, например, другому департаменту.
Data-mesh-архитектуру реализовал крупнейший американский банк JPMorgan Chase. С помощью этого подхода он структурировал data lakes в виде каталога, чтобы обеспечить к ним более простой доступ и легкое совместное использование.
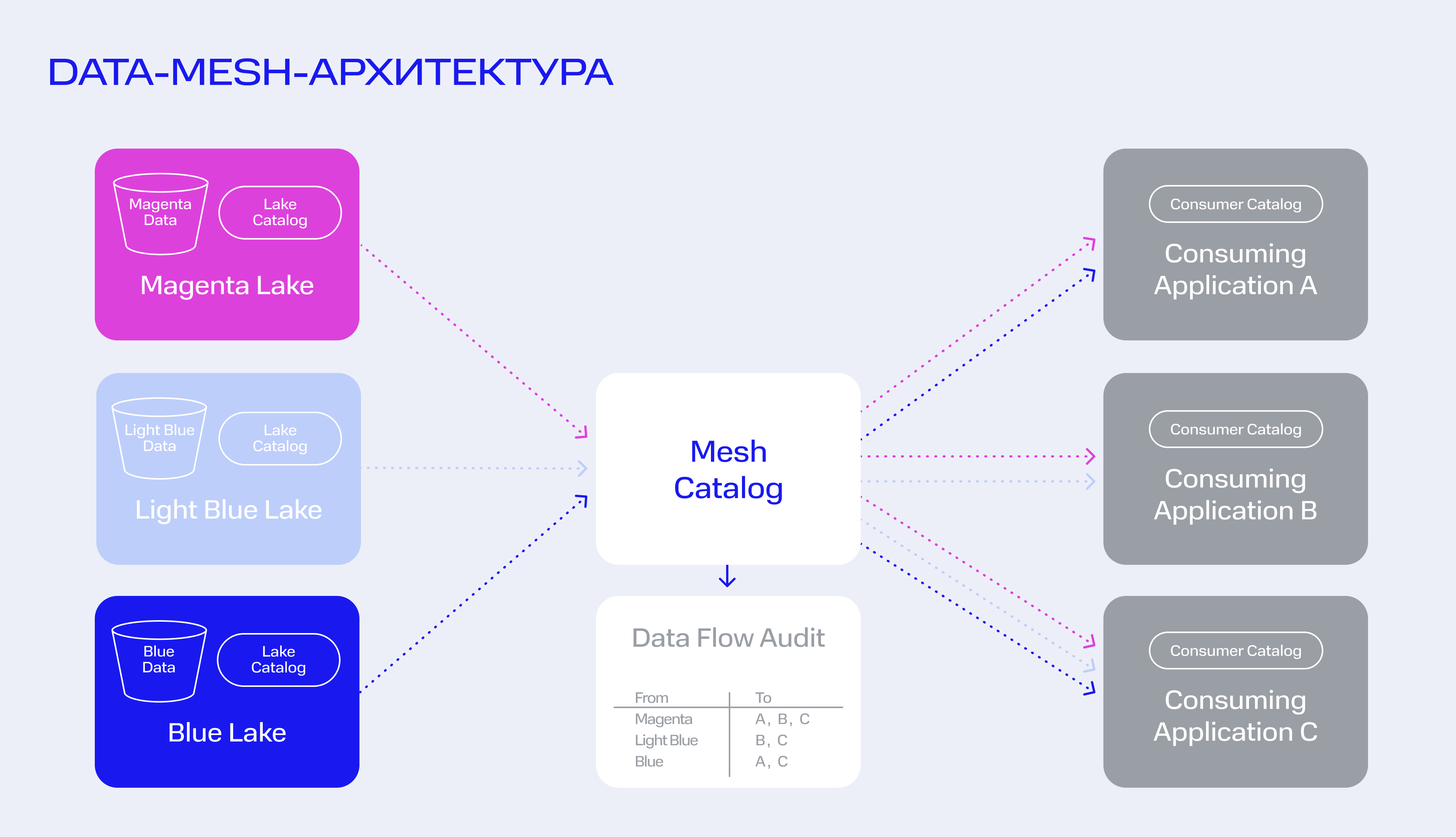
Технологическая платформа Intuit, которая разрабатывает финансовое программное обеспечение, также заинтересовалась концепцией Data mesh. В частности, идеей, когда за данные отвечают локальные команды. В компании изучили проблемы, с которыми сталкиваются специалисты, и на этой основе разработали стратегию управления данными. Она дает возможность командам легко проектировать, развивать и описывать высококачественные системы данных так, чтобы другие пользователи могли их применять.
Хранение данных в облачных сервисах
Финансовые компании собирают большие объемы данных — более 2 Пбайт. Чтобы с ними работать, нужна data-инфраструктура, развертывать которую внутри крупной компании — дорого и сложно. Задачу упрощают облачные сервисы, которые предоставляют свою архитектуру для управления данными. Благодаря этому финтех-компании могут быстрее выводить новые продукты на рынок и оптимизировать бизнес-процессы без вложений в дорогостоящее оборудование.
Последние события в мире привели к тому, что облачные провайдеры стали уходить из России. Выбор подходящего поставщика осложняется тем, что не все учитывают особенности финансовых организаций, когда предлагают различные решения по хранению и обработке данных.
В общемировой практике есть тренд по стандартизации облачных сервисов и провайдеров услуг. Их внедрением, доработкой и обсуждением с участниками рынка занимаются отдельные организации. В России на данный момент разрабатываются единые требования к облачным сервисам и созданию системы сертификации. Эта работа ведется в том числе на площадке Ассоциации ФинТех (АФТ).








