Содержание:

Ну, очень большие витрины
Качество бизнес-решений сегодня полностью зависит от качества используемых данных. Поэтому во многих компаниях все большую популярность набирает сервис DQaaS (Data Quality as a Service). Есть такой сервис и у нас. В основе него лежит программный инструмент проверки качества данных, а также к нему прилагается инженер по качеству данных (КД), который оперативно настроит проверки КД нужных витрин, проанализирует результаты и предоставит выводы по итогам анализа.
Для ML-моделей банка используются большие данные: в каждой ключевой витрине более 10 млн строк. Это информация о количестве клиентов, заявок на кредит, депозитов и так далее.
Конечно, модели работают не с сырыми данными, а с уже агрегированными, то есть часть вопросов с их качеством снята на более ранних этапах. Однако нам необходим метод сверки данных от среза к срезу, например от месяца к месяцу или от недели к неделе, это связано с особенностями работы моделей. При их построении используется некая выборка данных (семпл), проверяются показатели производительности модели и ее эффективность. И важно от среза к срезу проверять, что данные не поменялись драматически. Например, если модель строилась для выборки «30% мужчин, 70% женщин, 50% мужчин в возрасте до 45 лет», то и применяться она должна на таких же данных. Но если в новой выборке уже 90% мужчин, из них 70% старше 50 лет, модель может работать неэффективно. Яркий пример отклонений — изменения параметров выборки посетителей кафе во время ковида: доходы общепита кардинально изменились в связи с изоляцией, люди резко сократили траты на кафе, бары и офлайн-магазины, но в то же время объемы онлайн-покупок выросли в несколько раз.
Open Source нам поможет?
Запуская пилотный проект, мы решили поискать для проверки качества данных Open Source-инструмент. Есть самые разные открытые библиотеки, в том числе Pandas Profiling, Ydata_quality, Deepchecks, Great Expectations, TensorFlow Data Validation. И это только те, с которыми я лично работал на Python.
С помощью этих библиотек можно узнать много нового о своих данных. Например, отследить drift — ситуации, когда данные обучения и данные вывода/инференса различаются, и распределение входных признаков, на котором обучалась модель, смещается. Увидеть аномалии, оценки минимума-максимума, изучить встроенные отчеты (в ряде проектов есть красивые визуализации). А начать работу с анализом качества данных может любой аналитик или инженер. Для этого нужны минимальные знания Python: установить библиотеку, вызвать ее, подготовить датасеты с данными. Правда, self-service подразумевает отсутствие и таких знаний.
Оказалось, что разное свободное ПО дает приблизительно одинаковые возможности, разница — в отдельных специфических «фишках». Выявились и серьезные недостатки: некоторые решения не работают с большими объемами данных свыше 1 млн строк.
Второй негативный момент — зависимость от внешних разработчиков: если не хватает какого-то функционала, придется ждать, когда появится обновление библиотеки, либо дорабатывать ее самостоятельно.
Другой важный аспект — несовместимость с ранее установленными библиотеками. Если моделисты построили модели на определенных версиях библиотек, то при установке библиотек качества данных возможен конфликт версий.
Взвесив все возможности и ограничения, мы решили разработать собственную библиотеку и свой движок workflow по работе с качеством данных для Self-Service Data Quality (DQ).
Особенности движка для работы с качеством данных
Мы разработали процесс контроля качества данных для моделей, в рамках которого можно делать настраиваемые проверки качества данных любой сложности с графической визуализацией, возможностью подключения к любому источнику данных, прозрачной ролевой моделью доступа и рассылкой имейл-уведомлений о результатах проверок.
Мы разработали собственный набор метрик для оценки качества данных. Они позволяют оценивать ключевые показатели для числовых переменных (рассчитываются в абсолютном и долевом соотношении):
-
количество заполненных строк;
-
количество пустых строк;
-
медианное значение;
-
среднее значение;
-
минимальное значение;
-
максимальное значение;
-
суммарное значение по переменной на срез;
- PSI (Population Stability Index), который показывает состав конкретного поля.
Показатель PSI тяжеловесен в расчете, поэтому он не рассчитывается для всех столбцов витрины. Проводится первичная оценка по вышеуказанным метрикам, и только если необходима детализация, запускается расчет PSI.
Для каждой метрики можно задать доверительный интервал отклонения, то есть указать, что считать аномалией. Например, для количества заполненных строк устанавливаем порог 5%. Значит, если количество заполненных строк изменится менее, чем на 5% по сравнению с предыдущим срезом, это считается нормой.
Этот набор ключевых метрик сформирован на основе опыта наших специалистов. Но мы, конечно, постоянно следим за появлением инноваций на рынке, и при необходимости будут реализованы новые метрики.
Дополнительно выявлять аномалии помогает модель Isolation Forest. Она хорошо работает с большими объемами данных. Используется готовая библиотека Python Scikit-learn, известный пакет Python для задач Data Science и Machine Learning. Устроено это так. Из выборки берется произвольная переменная, оценивается минимальное и максимальное значение, после чего определяется некое произвольное значение между минимумом и максимумом. Таким образом, вся выборка делится на две подвыборки, имеющих вид ансамбля деревьев. Затем берется другая переменная, и процесс повторяется до тех пор, пока в каждом листе дерева не останется по одной записи или они окажутся схожими. Далее оценивается путь от корня дерева до каждого листа: чем этот путь короче, тем выше вероятность, что это аномалия.
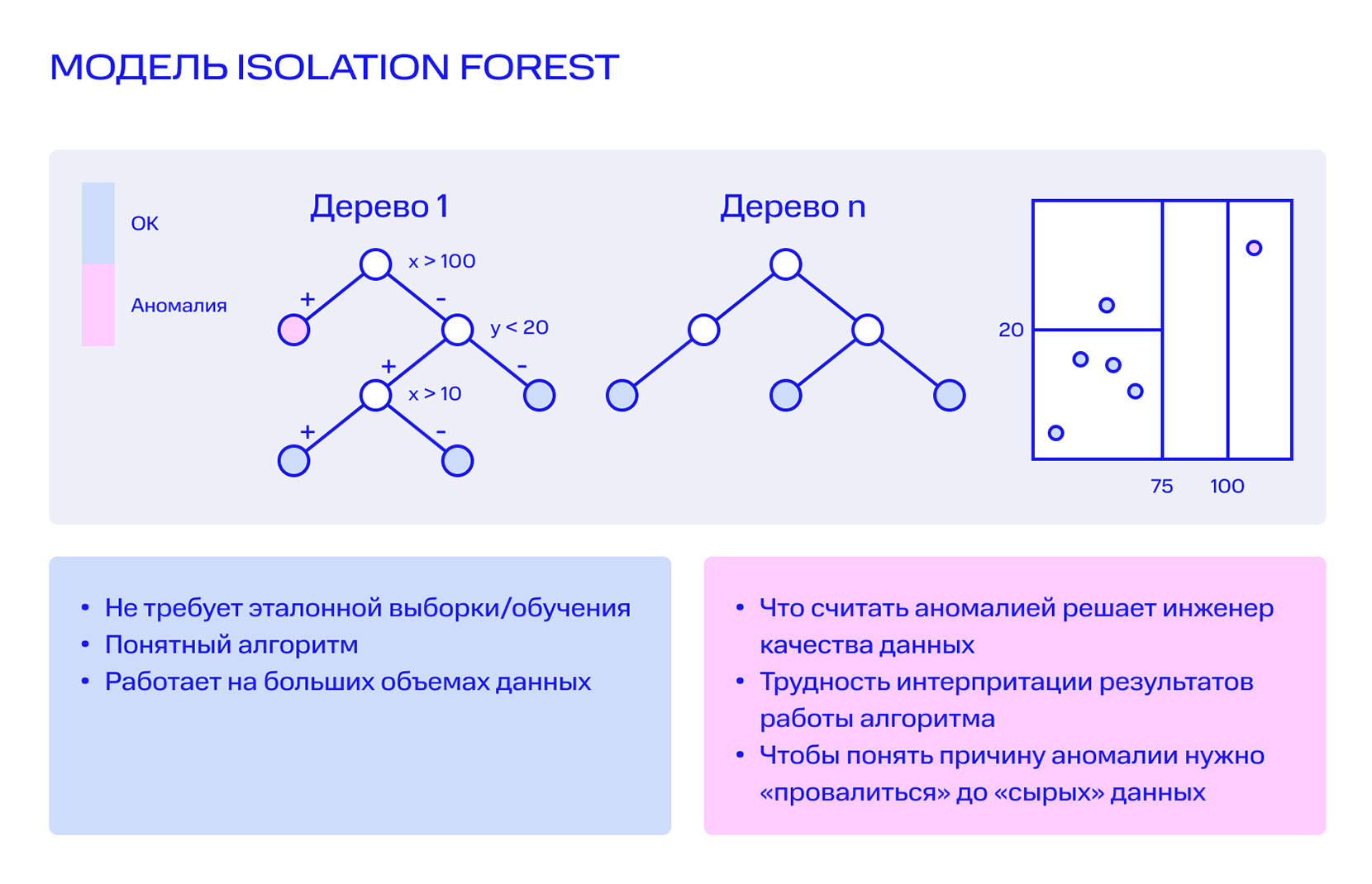
Замечательное свойство этого подхода заключается в том, что он не требует эталонной выборки и обучения. Можем построить витрину, взять историю по срезам за два года и сразу применить алгоритм. К минусам метода можно отнести значительную субъективность результатов: что считается аномалией, определяет сам инженер качества данных.
То есть инженер может выбирать, каким инструментом оценки данных воспользоваться в каждом конкретном случае.
В целом, базовый набор метрик качества, хоть и выглядит просто, дает возможность четко определить, есть ли какие-то проблемы с данными. Метод Isolution Forest ловит аномалии по-своему, и его указания служат сигналом для дополнительной проверки. В любом случае выявленные системой аномалии вручную проверяет инженер по качеству данных. Чтобы понять причины аномалии, ему приходится проваливаться до сырых данных и разбираться с ними.
Принципы разработки и технологический стек движка Self-service DQ
Путь к MVP был постепенным: вначале реализовали базовые метрики, затем возможность настраивать доверительный интервал и так далее. Сегодня Self Service DQ уже доступен для самостоятельной работы аналитика.
На рисунке горизонтальными стрелками показан процесс, в котором участвует аналитик. Витрины рассчитываются в SQL-Server или Cloudera Impala. Это общебанковская аналитическая платформа данных на базе массово-параллельного механизма интерактивного выполнения SQL-запросов к данным, хранящимся в Apache Hadoop.
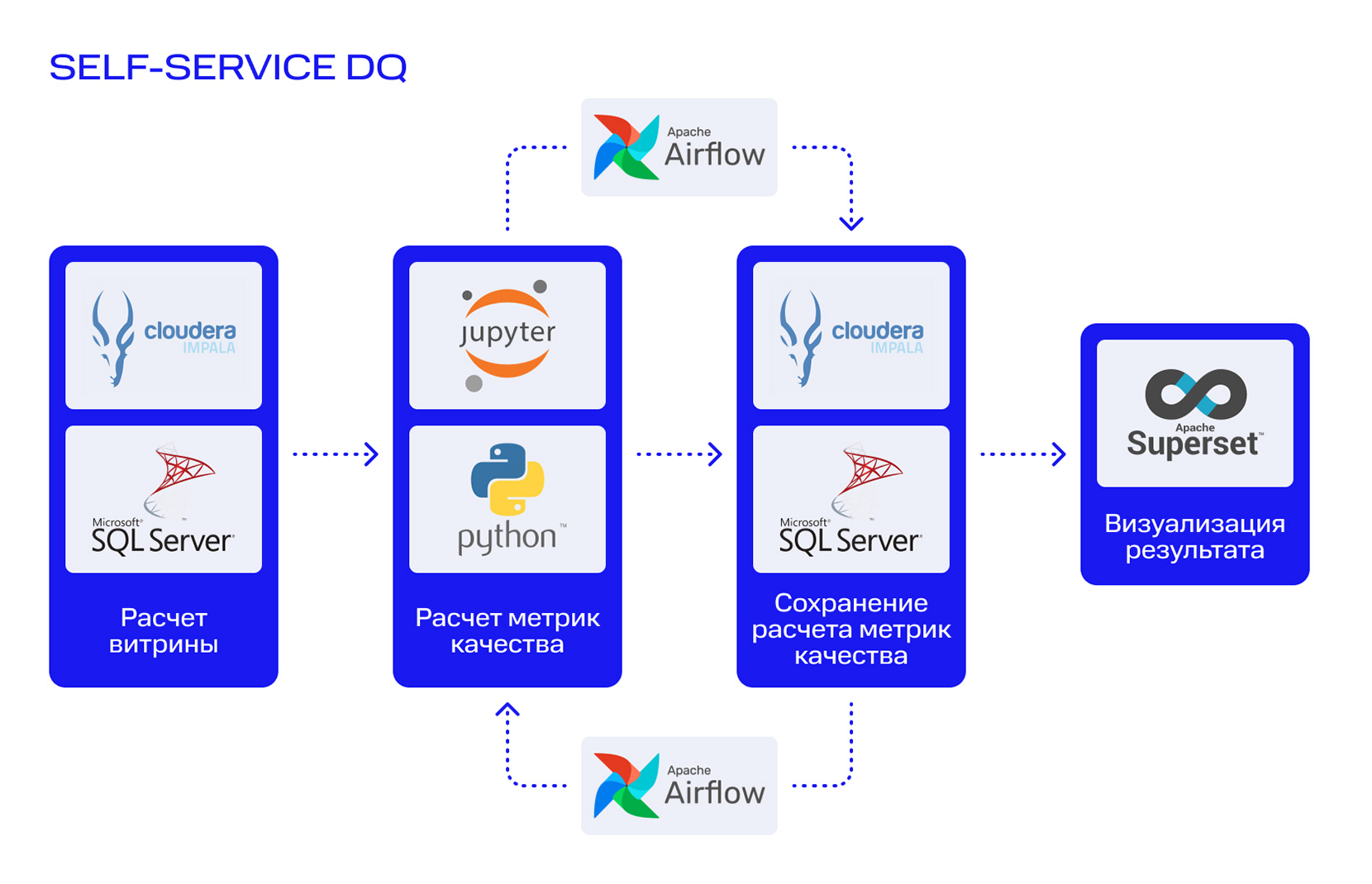
Проверки написаны на SQL и Python через Jupyter notebook — там рассчитываются метрики качества, которые сохраняются в Hadoop. История метрик нужна для того, чтобы видеть динамику показателей за несколько лет или оперативно посмотреть всплески данных в нужный интервал времени.
Данные метрик качества визуализируются в Apache Superset. Благодаря тому, что проверки унифицированы и их результаты хранятся в одной таблице, нам удалось построить единый шаблон дэшборда. Это очень важный шаг на пути к self service-инструменту. Для каждой новой витрины не нужно строить отдельный дэшборд. Как только завершен процесс проверки качества данных, сразу доступен и дэшборд.
Для организации режима самообслуживания мы разработали страницу, на которую может зайти любой аналитик и ввести информацию, чтобы настроить расписание проверок качества данных таблицы или витрины. Тут все просто: специалист задает название таблицы, вводит частоту запуска проверок, указывает, какие поля необходимо исключить из проверки, если это необходимо. Он также указывает нужные доверительные интервалы, то есть процент отклонения данных от предыдущего среза. Если данные изменились на меньший процент, это не является инцидентом КД, если на больший — является. Все эти данные записываются в настроечную таблицу.
Аналитик задает минимальные настройки, и далее механизм функционирует в автоматическом режиме. На этой стадии работают два основных решения:
- Оркестратор процессов анализа качества данных Apache Airflow. Он создает DAG (направленный ациклический граф), объединяющий вместе все задачи проверки через настроенные зависимости и отношения. Эти зависимости определяют, как именно должна отработать цепочка задач (data pipeline). Задачи, входящие в состав DAG, в Apache Airflow называются операторами (operator).
- Инструмент визуальной аналитики Apache Superset. Результаты работы DAG Airflow автоматически записываются в таблицу. С ней и работает инструмент Superset.
К работе этих решений аналитик не имеет отношения, это зона ответственности инженеров команды анализа данных и моделирования.
Запуск DAG Airflow в одном сеансе проверки может производиться многократно. Он использует механизм планировщика (Scheduler), который отслеживает все созданные задачи. Он с регулярной периодичностью сканирует настроечную таблицу, в которой хранится информация о том, какие витрины с какой частотой нужно проверять. По умолчанию планировщик три раза в день проверяет доступные для запуска задачи, и если такие есть — запускает их. Если заданная аналитиком витрина еще не обновилась, DAG будет ожидать события, и запустится позже в автоматическом режиме.
Возможности визуальной аналитики при оценке качества данных
С помощью инструмента Apache Superset производится визуализация рассчитанных метрик качества данных. Используются три ключевых варианта представления аналитических результатов:
-
Общая информация о витрине в целом.
-
Круговая диаграмма, которая отражает статистику по отклонениям всех переменных в витрине. Оранжевым цветом помечаются те, в которых выявлены отклонения. Синим — переменные, которые не отклонились. Рядом та же информация отображается в виде столбчатой диаграммы за всю накопленную историю проверок КД.
-
Детальные данные в виде столбчатых диаграмм, которые отражают состояние переменных за всю историю проведения проверок КД. Отражается количество уникальных значений пустых строк, а также медиана, минимальные и максимальные значения.
-
Детализированная информация о количестве заполненных строк и суммарному значению по атрибуту — по сути, сырые данные. Если, например, мы видим, что отклонилось максимальное значение, но при этом медиана стоит на месте, значит, для какого-то небольшого количества записей клиентов, заявок и других данных произошло изменение. Есть выброс, при этом медиана не сдвинулась в сторону. Или, скажем, мы видим, что в процентом соотношении количество пустых строк по одной переменной, например, возрасту, увеличилось на 300%. Это ведь много! Но если посмотреть детальные данные, можно увидеть, что в предыдущем срезе из 10 миллионов было три строки с заполненным возрастом, а сейчас стало 10 или 11. Несмотря на 300%, речь идет об очень малых значениях, и инцидентом это не считается.
Суммарное значение по атрибуту — очень полезный инструмент для анализа витрин, предназначенных для моделей. Дело в том, что дата-инженер обычно строит большое количество полей. И некоторые из них оказываются похожими. Чтобы не писать логику переменной заново, он копирует предыдущую переменную. Условие ограничения меняется. Например, некое событие за 1 месяц/за 3 месяца/за 6 месяцев и т.д. Если в момент переноса дата-инженера отвлекли, он может не изменить логику. Тогда на выходе получаем две разные переменные, имеющие абсолютно одинаковую логику. Сумма по атрибуту покажет, что срез по переменной А и по переменной Б дает одну и та же сумму, то есть они дублируют друг друга.
Перспективы развития сервиса Self-service DQ
Банк планирует максимально автоматизировать управление качеством данных, распространить опыт проверок в режиме самообслуживания на большее количество данных и ускорить реагирование на инциденты.
Кроме того, у нас есть наработки по отображению всего процесса построения витрины: от источника данных до конечного потребителя (построение data lineage). В планах объединить этот инструмент и Self-service DQ таким образом, чтобы в случае инцидента с качеством данных на визуальном представлении были отмечены цветом таблицы-источники, которые были «задеты» этим инцидентом.
Также в Газпромбанке идет внедрение новой платформы данных, в том числе платформы Data Science. Инструмент Self-service DQ станет неотъемлемой частью этой платформы.